

基本情報技術者試験のアルゴリズム問題でハフマン符号化について出題されていましたね!私も解いてみたのですが、C言語であればポインタを使ったらもうちょっと分かりやすいプログラムになるんじゃなかなぁと思ってこのページを作ってみました。
このページではハフマン符号化についての解説と、そのプログラムの紹介を行います。
プログラムに下記のバグがありましたので2020/11/22に修正しました
- セグメンテーションフォールトが発生する
- 文字が1種類の場合にデコードできない
Contents
ハフマン符号化の概要
ハフマン符号化はハフマンという人によって考案された符号化方式です。可逆圧縮の符号化方式ですので、符号化した結果は完全に元のデータに復号化することができます。ハフマン符号化は下記の4つのステップにより符号化を行います。
スポンサーリンク
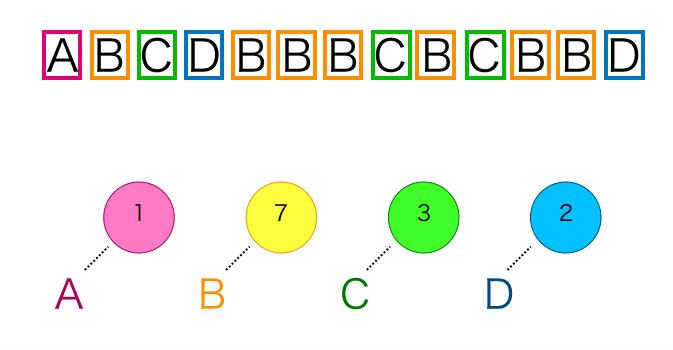
文字の出現回数のカウント
まず入力ファイル中の文字列にどの文字が何回出現するかをカウントします。
スポンサーリンク
ハフマン木の生成
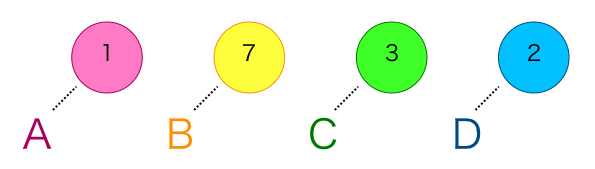
そしてその出現回数に応じてハフマン木というものを生成します。
まず、先ほどカウントした出現回数を値とした節を、その文字が出現した順番(出現回数の順ではない)に追加します。
以降、親が登録されていない節が1つになるまで下記の①から③を繰り返すことで生成できます。
①親が登録されていない節の中から、出現回数の最も少ない節とその次に少ない節を選択(同じ出現回数のものがあった場合は、先に節として追加した方を選択する)
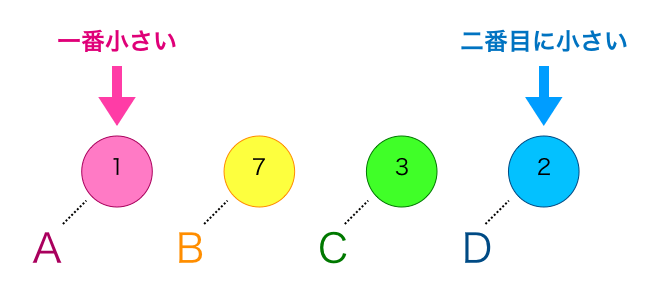
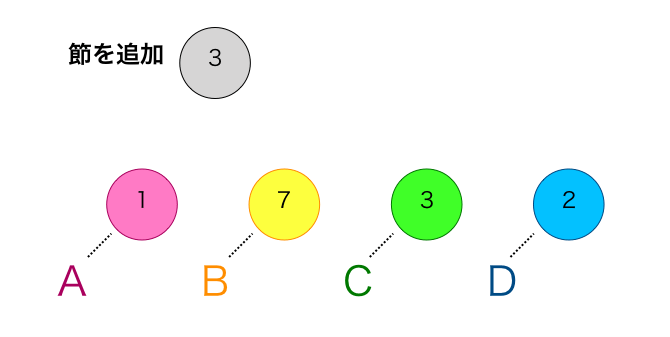
②選択した2つの節の出現回数の和を出現回数とした新たな節を追加
③その追加した節を、選択した2つの節の親として登録。さらにその追加した節の左の子として出現回数の最も少ない節を、右の子として出現回数の二番目に少ない節を登録
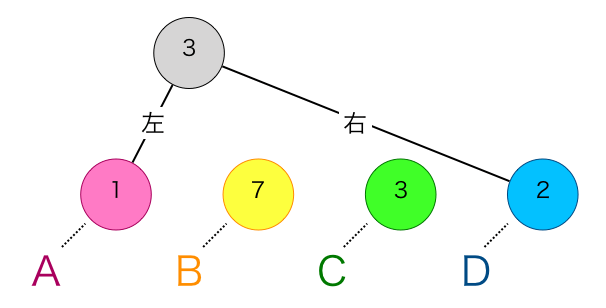
これらを親の持たない節が一つになるまで繰り返すと、下の図のようになります。
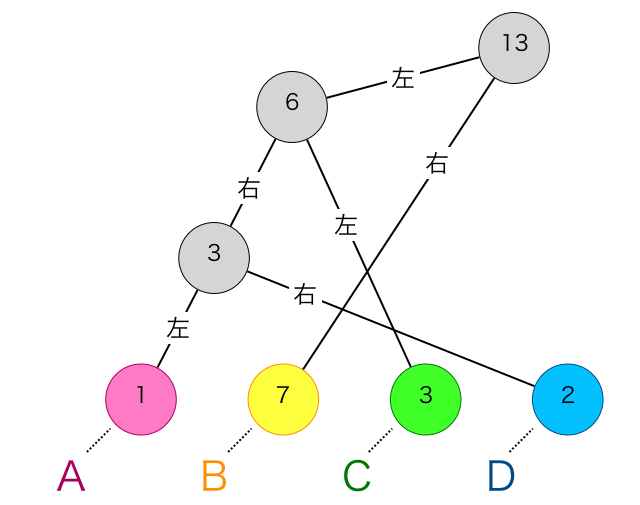
左の子が右にいたり、線が重なっていて分かりにくいので、親子関係を崩さず整理すると、下のように木のような形にできます。
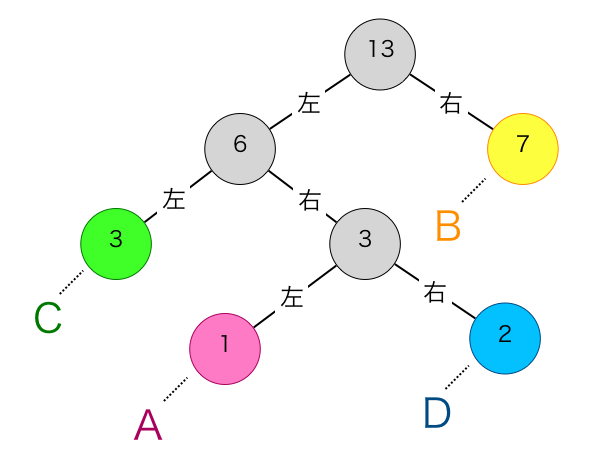
親の持たない節を根、子を持たない節を葉と呼びます。文字に対応する節は全て葉となります。
各文字の符号の算出
各文字への符号は、文字に対応する葉から根へ辿っていくことで算出することができます。具体的には、下記を葉から根に辿り着くまで繰り返し、得られたビットを得られた順に右側から並べたビット列が、その文字の符号となります。
①注目する節が親から見て左側の子である場合はビット0を、右側の子である場合はビット1を割り当てる
②親を次に注目する節とする
先ほど作成したハフマン木を用いて、”D”に対する符号の算出の実例を示します。
まず①を実行します。最初の節は”D”に対応する下図の紫枠で囲った節です。
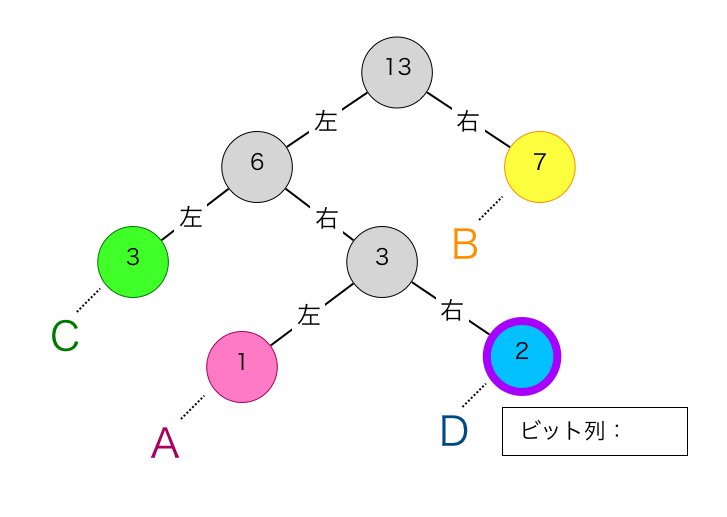
この節は、親から見て右の子なので、ビット1を割り当てます。
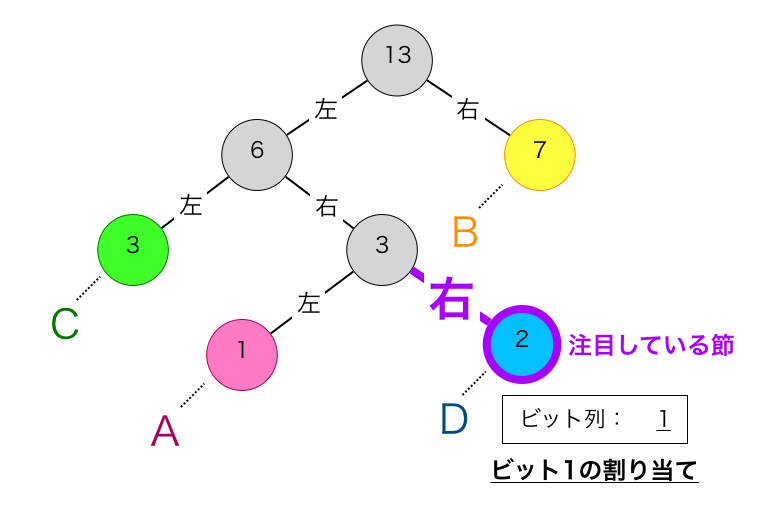
続いて②を実行します。これにより注目する節が下図の紫枠に移動します。
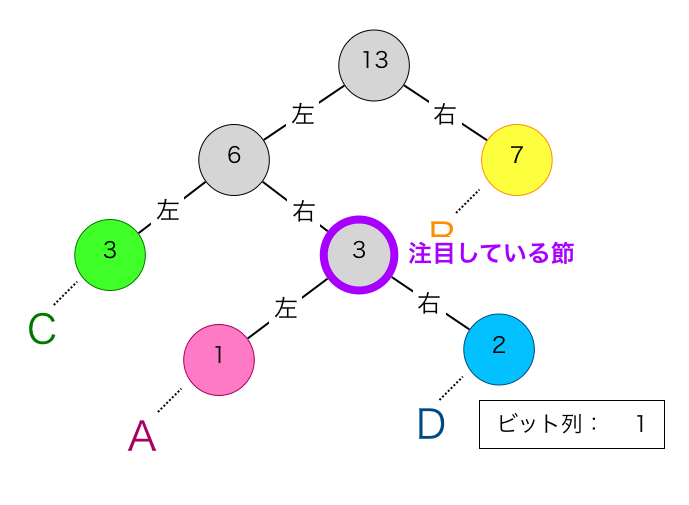
二回目の①を実行します。この節も親から見て右の子なので、ビット1を割り当てます。このビット1を現在のビット列の一番左側に割り当てます。これによりビット列は”11″となります。
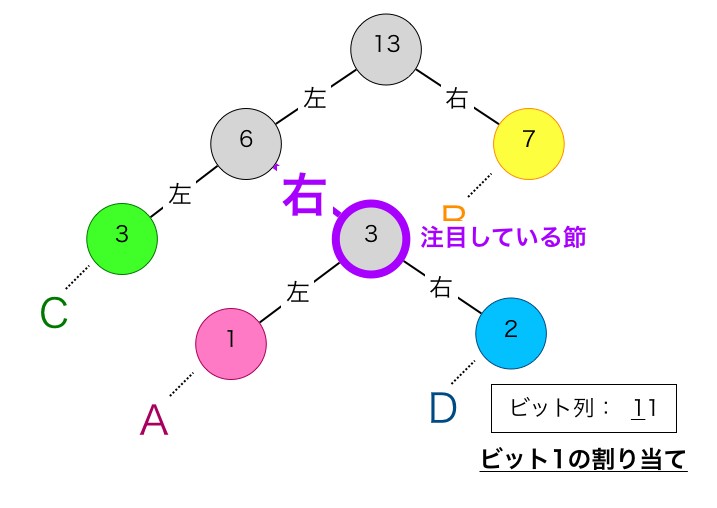
二回目の②を実行します。これにより注目する節が下図の紫枠に移動します。

三回目の①を実行します。この節は親から見て左の子なのでビット0を割り当てます。このビット0をビット列の一番左側に割り当てます。これによりビット列はは”011″となります。
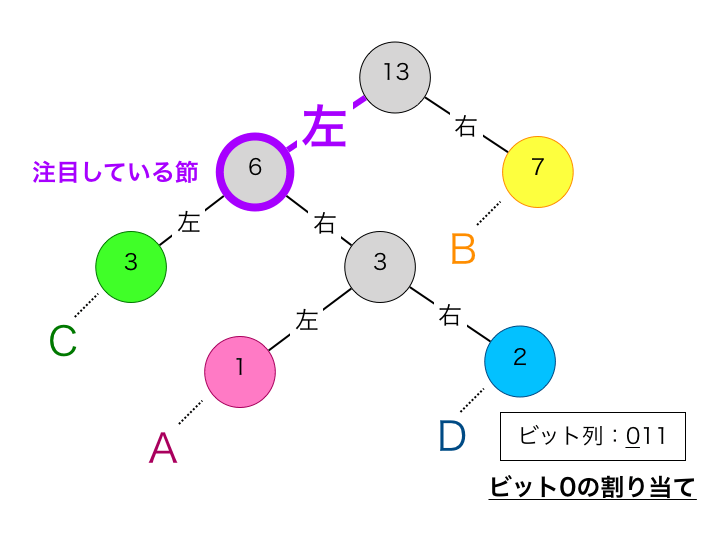
三回の②を実行します。これにより注目する節が下図の紫枠に移動します。この節は根なので、この時点で符号の算出処理は終了であり、その時点のビット列”011″が文字”D”を符号化した結果となります。

これらを、入力データに含まれる文字全てに対して実行することで、入力データの符号化を行うために必要な符号を全て算出することができます。
スポンサーリンク
データの符号化
最後に入力ファイルの各文字を対応する符号に置き換えを行います。これにより各文字は符号の並び(ビット列)に変換されます。
やり方は単純で、入力ファイルの先頭の文字から順に、その文字の符号(ビット列)に置き換えていくだけです。
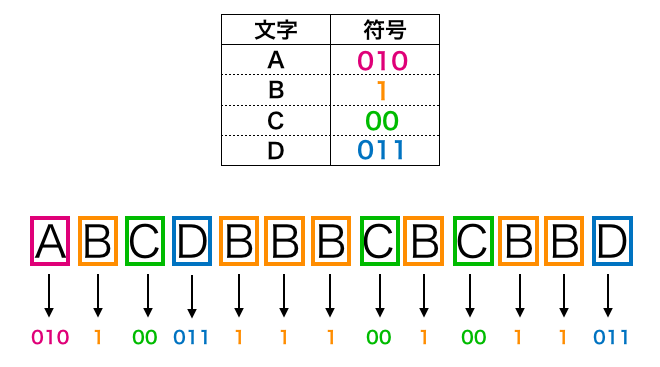
実際に先ほど作成したハフマン木から算出された符号を用いて文字列”ABCDBBBCBCBBD”を符号化する様子が上の図になります。
なんだか文字列が多くなって全然圧縮されているように見えないかもしれませんが、ビット列は1文字1ビットで表現することができますので、ハフマン符号化することによりファイルサイズは(データ部分だけだと)、22ビットになります。一方、英数字は一般に1文字8ビットのサイズが必要ですので、圧縮しない場合だと13文字のデータだと104ビット必要であり、ハフマン符号化することによりファイルサイズを圧縮できていることが分かると思います。
スポンサーリンク
プログラムの例
下記がハフマン符号化のC言語ソースコードになります。対応しているの ‘\0’ を除く1バイト文字からなるテキストファイルです。英文だけのファイルであればこのプログラムでハフマン符号化できるはずです。
#include <stdio.h>
#include <stdlib.h>
typedef struct node NODE;
typedef struct code CODE;
/* ハフマン木の節データ */
struct node {
NODE *parent;
NODE *left;
NODE *right;
NODE *next;
unsigned int freq;
char chr;
};
/* ハフマン符号データ */
struct code {
char chr;
int value;
char bit;
CODE *next;
};
/* 指定されたchrを持つ節を探す関数 */
/* 見つかった場合はその節へのポインタ、
見つからなかった場合はNULLを返却 */
NODE *searchNode(NODE *node, char chr){
while(node != NULL){
if(node->chr == chr){
return node;
}
node = node->next;
}
return node;
}
/* 節を追加する関数 */
NODE *newNode(char chr){
NODE *node;
node = (NODE*)malloc(sizeof(NODE));
if(node == NULL){
return NULL;
}
/* 親や子を指すポインタはNULLで初期化 */
node->parent = NULL;
node->left = NULL;
node->right = NULL;
node->next = NULL;
node->freq = 1;
node->chr = chr;
return node;
}
/* 文字の出現関数をカウントし、
その出現関数を持つ節を生成 */
NODE *makeNodes(char *filename){
NODE *head;
NODE *tail;
NODE *add;
NODE *search;
char chr;
FILE *fp;
head = NULL;
tail = NULL;
/* ファイルをオープン */
fp = fopen(filename, "r");
if(fp == NULL){
printf("%s open error\n", filename);
return NULL;
}
/* 全文字読み終わるまで1文字ずつ読み取り */
while((chr = fgetc(fp)) != EOF){
/* その文字に対応する節を探索 */
search = searchNode(head, chr);
if(search == NULL){
/* 節がない場合は新しく節を追加 */
add = newNode(chr);
if(add == NULL){
printf("node malloc error\n");
fclose(fp);
return NULL;
}
/* 最初の節の場合はheadとtailにその節を指させる */
if(head == NULL){
head = add;
tail = add;
} else {
/* すでに節がある場合は終端に節を追加 */
tail->next = add;
tail = add;
}
} else {
/* その文字に対応する節がある場合は出現関数をカウントアップ */
search->freq++;
}
}
fclose(fp);
return head;
}
/* 親のいない節の中から一番出現関数が少ない節と、
二番目に出現回数が少ない節を探索する関数 */
/* 一番出現回数が少ない節はleftに
二番目に出現回数が少ない節はrightに指させる */
void getChild(NODE **left, NODE **right, NODE *head){
/* 出現回数の最小値を格納する変数 */
unsigned int first = 999999;
/* 出現回数の二番目に小さい値を格納する変数 */
unsigned int second = 999999;
*left = NULL;
*right = NULL;
/* リストの先頭から探索 */
while(head != NULL){
if(head->parent == NULL){
/* 出現回数が一番少ないかどうかを判断 */
if(first > head->freq && second > head->freq){
first = head->freq;
*right = *left;
*left = head;
/* 出現回数が二番目に少ないかどうかを判断 */
} else if(second > head->freq){
second = head->freq;
*right = head;
}
}
/* headを次の節へ進ませる */
head = head->next;
}
}
/* ハフマン木を作成する関数 */
void makeHuffmanTree(NODE *head){
NODE *left = NULL;
NODE *right = NULL;
NODE *tail = NULL;
NODE *add = NULL;
if(head == NULL){
printf("head is NULL\n");
return ;
}
/* リストの終端までtailを移動 */
tail = head;
while(tail->next != NULL){
tail = tail->next;
}
/* 出現回数の少ない二つの節を取得 */
getChild(&left, &right, head);
/* 親のいない節が2つ未満になるまでループ */
while(left != NULL && right != NULL){
/* 新しいノードを追加 */
/* 文字情報は'\0'とする */
add = newNode('\0');
if(add == NULL){
printf("malloc error\n");
return ;
}
/* 追加した節はleftとrightの親となるようにパラメータ設定 */
left->parent = add;
right->parent = add;
add->left = left;
add->right = right;
add->freq = left->freq + right->freq;
/* 追加した節をリストの終端に登録 */
tail->next = add;
tail = add;
/* 出現回数の少ない二つの節を取得 */
getChild(&left, &right, head);
}
}
/* 文字にハフマン符号を割り当て、
その情報をCODE構造体に格納する関数 */
CODE *makeHuffmanCode(NODE *node){
NODE *child = NULL;
NODE *parent = NULL;
CODE *code = NULL;
CODE *top = NULL;
CODE *add = NULL;
/* 符号(ビット列) */
int value;
/* 符号のビット数 */
int bit;
/* 葉全てに符号を割り当てたらループ終了 */
/* 葉以外の節の文字は'\0' */
while(node != NULL && node->chr != '\0'){ /* "&"を"&&"に修正@2020/11/22 */
/* 符号とそのビット数を0に初期化 */
value = 0;
bit = 0;
/* CODE構造体を追加 */
add = (CODE*)malloc(sizeof(CODE));
if(add == NULL){
printf("malloc error\n");
return NULL;
}
/* 追加したCODE構造体の文字を設定 */
add->chr = node->chr;
/* childは今注目している節へのポインタ */
child = node;
/* parentは今注目している節の親へのポインタ */
parent = node->parent;
/* 葉から根まで親を遡っていく */
/* 根の節はparentがNULL */
while(parent != NULL){
/* 親から見て今注目している節が左の子の場合 */
if(parent->left == child){
/* ビット列(value)の一番左へビット0を追加 */
value = value + (0 << bit);
/* 親から見て今注目している節が右の子の場合 */
} else if(parent->right == child){
/* ビット列(value)の一番左へビット1を追加 */
value = value + (1 << bit);
}
/* ビット列のビット数を1増やす */
bit++;
/* 今注目している節の親を、新たな注目節に更新 */
child = parent;
/* 親も親の親に更新 */
parent = parent->parent;
}
/* 符号を求め終わったので、
追加したCODEに符号そのものとそのビット数を設定 */
add->value = value;
add->bit = bit;
/* 文字が1種類の場合の例外処理を追加@2020/11/22 */
if(add->bit == 0) {
/* 文字が1種類の場合の処理 */
add->bit = 1;
}
/* CODE構造体がまだ一つもない場合 */
if(code == NULL){
code = add;
top = code;
code->next = NULL; /* NULL設定を追加@2020/11/22 */
/* CODE構造体がすでにある場合は最後尾に追加 */
} else {
code->next = add;
code = code->next;
code->next = NULL; /* NULL設定を追加@2020/11/22 */
}
/* 次の節に対して符号を算出 */
node = node->next;
}
return top;
}
/* nodeが先頭を指すNODE構造体のリストを全削除する関数 */
void freeNode(NODE *node){
NODE *next;
while(node != NULL){
next = node->next;
free(node);
node = next;
}
}
/* codeが先頭を指すCODE構造体のリストを全削除する関数 */
void freeCode(CODE *code){
CODE *next;
while(code != NULL){
next = code->next;
free(code);
code = next;
}
}
/* 引数chrの文字をchrメンバに持つCODE構造体を探索する関数 */
CODE *searchCode(CODE *head, char chr){
while(head != NULL){
if(head->chr == chr){
return head;
}
head = head->next;
}
return NULL;
}
/* 符号化を行なってファイルに書き出しする関数 */
void encodeFile(char *outname, char *inname, CODE *head){
FILE *fi;
FILE *fo;
CODE *code;
unsigned char byte;
char emptyBits;
unsigned int textlength;
int mask;
char oneBit;
unsigned int headerSize;
char chr;
int i;
/* 終端を表す文字を格納 */
char terminal = '\0';
/* 入力ファイルを開く */
fi = fopen(inname, "r");
if(fi == NULL){
printf("%s open error\n", inname);
return ;
}
/* 入力ファイルの文字数をカウント */
textlength = 0;
while((chr = fgetc(fi)) != EOF){
textlength++;
}
/* 入力ファイルを一旦クローズ */
fclose(fi);
/* 出力ファイルを開く */
fo = fopen(outname, "wb");
if(fo == NULL){
printf("%s open error\n", outname);
/* 不要なfcloseを削除@2020/11/22 */
return ;
}
/* ヘッダーを書き込む */
headerSize = 0;
code = head;
/* CODE構造体のリストの先頭から終端まで、
文字の符号化情報をヘッダーとして書きだす */
while(code != NULL){
/* まず文字を書き込む */
fwrite(&(code->chr), sizeof(code->chr), 1, fo);
/* 符号化文字のビット数を書き込む */
fwrite(&(code->bit), sizeof(code->bit), 1, fo);
/* この文字のエンコード結果を書き込む */
fwrite(&(code->value), sizeof(code->value), 1, fo);
headerSize += sizeof(code->chr) + sizeof(code->bit) + sizeof(code->value);
/* 次の文字の符号化情報書き出しに移る */
code = code->next;
}
/* ヘッダーの終端として'\0'と文字数を書き出す */
fwrite(&terminal, 1, 1, fo);
fwrite(&textlength, sizeof(textlength), 1, fo);
headerSize += 1 + sizeof(textlength);
printf("Header Size is %d bytes\n", headerSize);
/* 入力ファイルを開く */
fi = fopen(inname, "r");
if(fi == NULL){
printf("%s open error\n", inname);
return ;
}
/* バイトデータを0で初期化 */
byte = 0;
/* バイトデータの空きビット数を8に設定 */
emptyBits = 8;
/* ファイルから1文字ずつ読み込み */
while((chr = fgetc(fi)) != EOF){
/* 読み込んだ文字に対応するCODE構造体を取得 */
code = searchCode(head, chr);
/* 符号の最上位ビットからバイトデータへ詰め合わせ */
for(i = code->bit - 1; i >= 0; i--){
/* iビット目が1でそれ以外が0のビット列を作成 */
mask = 1 << i;
/* iビット目以外を0にしたのちiビット分右シフト */
oneBit = (code->value & mask) >> i;
/* バイトデータの空きビット数 - 1分左シフトして足し合わせ */
byte += oneBit << (emptyBits - 1);
/* 空いているビット数を1減らす */
emptyBits--;
/* 空いているビットが0になったらファイルへ書き出し */
if(emptyBits == 0){
fwrite(&byte, 1, 1, fo);
/* ファイルに書き出したので空きビット数を8、
byteを0で初期化 */
emptyBits = 8;
byte = 0;
}
}
}
/* 1バイト分つまらなかった分を最後にファイルへ書き出し */
if(emptyBits < 8){
fwrite(&byte, 1, 1, fo);
}
/* 開いていたファイルをクローズ */
fclose(fi);
fclose(fo);
}
int main(int argc, char* argv[]){
NODE *nodes;
CODE *codes;
char outname[256];
if(argc != 2){
printf("引数に入力ファイル名を指定してください\n");
return -1;
}
nodes = makeNodes(argv[1]);
makeHuffmanTree(nodes);
codes = makeHuffmanCode(nodes);
freeNode(nodes);
sprintf(outname, "huffman.enc");
encodeFile(outname, argv[1], codes);
return 0;
}プログラムの説明
ポイントだけ説明していきます。分からないところなどはコメントなどで質問していただければ回答します!
構造体の解説
まずプログラムに出現するNODE構造体とCODE構造体について解説します。
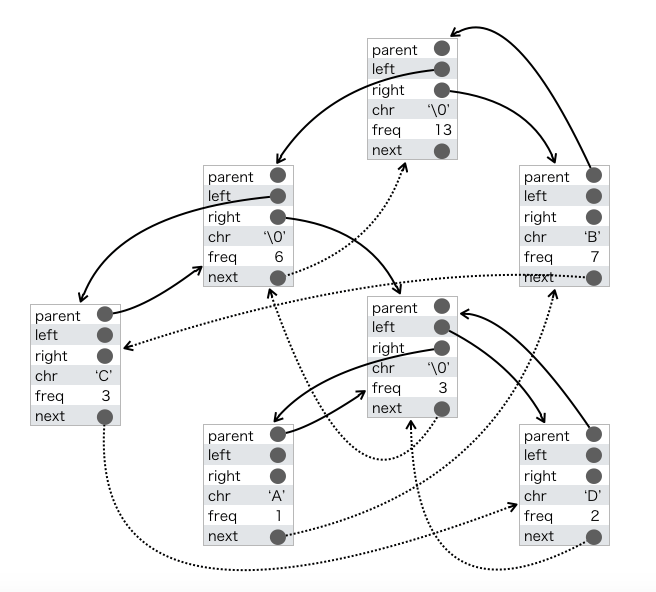
NODE構造体
NODE構造体はハフマン木の節に相当するデータです。
- parent:親へのポインタ
- left:左の子へのポインタ
- right:右の子へのポインタ
- freq:出現回数
- chr:文字
をそれぞれ表します。ハフマン木をこのNODE構造体に対応させると下のようになります。
NODE構造体はリスト構造として管理できるように下記のメンバも持たせています。
- next:次の節へのポインタ
節を追加するときや文字の出現回数をカウントアップするときのその文字の節の探索を行うため等にリスト構造と見立ててこの next を用います。
CODE構造体
CODE構造体は各文字の符号情報を格納するデータです。
- chr:文字
- value:符号(ビット列)
- bit:符号のビット数
- next:次の符号情報へのポインタ
こちらも next を用意し、リスト構造的に符号情報を管理します。
スポンサーリンク
文字の出現回数のカウント
文字の出現回数のカウントは主に makeNodes 関数で行なっています。
head は NODE構造体のリストの先頭を指すポインタ、tail は最後尾を指すポインタになります。
下記でオープンした入力ファイルから一文字ずつ読み込み、その文字に対応するNODE構造体を searchNode 関数で探索します。
/* 全文字読み終わるまで1文字ずつ読み取り */
while((chr = fgetc(fp)) != EOF){
/* その文字に対応する節を探索 */
search = searchNode(head, chr);searchNode関数は見ていただければ分かるように、単純にNODE構造体の先頭からリストを辿ってその文字の節を探索する処理を行なっています。
見つからなかった場合は下記でその文字に対応するNODE構造体を追加し、add ポインタにより追加したNODE構造体を指させます。
add = newNode(chr);addNode 関数は malloc でNODE構造体のメモリを確保し、NODE構造体の各メンバに初期値を格納する処理を行なっています。
続いてポインタ head が NULL であるかどうかの判断を行います。head はリスト構造の先頭を指すポインタであり、これが NULL ということはまだ節が1つもないということです。
なので、この場合は追加した節を先頭、そして最後尾として登録します。
head = add;
tail = add;逆に head が NULL でなければすでに他の節が存在するということなので、最後尾を指す tail 変数の次の要素として tail->next に add の指す先を指させます。さらにその指す先を新たな最後尾として tail に指させます。
tail->next = add;
tail = add;searchNode 関数でその文字の節が見つかった場合は、単純にその文字の節の出現回数をカウントアップします。
search->freq++;これらをファイル中の全文字に対して繰り返すことで、出現回数をカウントでき、ここで作成した節がハフマン木の葉となります。
スポンサーリンク
ハフマン木の生成
続いて行うのがハフマン木の生成です。文字の出現回数のカウントで生成した葉を基にハフマン木を生成していきます。
このハフマン木の生成は主に makeHuffmanTree 関数で行います。
まず下記により tail に NODE 構造体の最後尾を指させます。新たな節(NODE 構造体)を追加するときには、この tail の後ろ(next)へ追加していきます。
tail = head;
while(tail->next != NULL){
tail = tail->next;
}続いて getChild 関数により、親のいない節の中で出現回数が一番小さい節へのポインタ left と二番目に小さい節へのポインタ right を取得します。
getChild(&left, &right, head);getChild 関数は NODE構造体のリストの先頭 head から parent が NULL の NODE 構造体から、 freq が一番小さい NODE 構造体と二番目に小さい NODE 構造体を探索し、前者へのポインタを *left へ、後者へのポインタを *right に格納する処理を行います。
親のいない節が1つしかない場合は *right に NULL が格納されます。
なので、下記で親が2つ以上あるかどうかを判断して、1つしかない場合はハフマン木の作成(つまり makeHuffmanTree 関数)を終了します。
2つ以上ある場合は、親の作成に移ります。
まず下記の addNode 関数で NODE 構造体を1つ追加します。葉以外は文字に対応付かないので引数には “\0″(ヌル文字)を渡します。
add = newNode('\0');getChild 関数により取得した left と right の parent として登録します。
left->parent = add;
right->parent = add;続いて追加した構造体の left メンバに left を、right メンバに right を指させます。
add->left = left;
add->right = right;さらに left と right の freq の和を新たな NODE 構造体の freq とします。
add->freq = left->freq + right->freq;最後に、追加した NODE 構造体をリストの最後尾に追加し、最後尾を指す tail ポインタの指す先を更新します。
tail->next = add;
tail = add;これを getChild 関数で right が NULL になるまで繰り返すことでハフマン木を作成します。
各文字の符号の算出
符号の算出は makeHuffmanCode 関数で行っています。
NODE 構造体のリストを先頭から葉でなくなるまで文字の符号の算出を行います。
while(node != NULL && node->chr != '\0'){まず下記で CODE 構造体を追加し、
add = (CODE*)malloc(sizeof(CODE));その CODE 構造体の chr メンバに、今注目している葉である NODE 構造体の chr の値を格納します。
add->chr = node->chr;続いて今注目している NODE 構造体へのポインタを child に指させ、さらに親へのポインタを parent に指させます。
/* childは今注目している節へのポインタ */
child = node;
/* parentは今注目している節の親へのポインタ */
parent = node->parent;ここから、この parent が NULL になるまで、つまり parent が根を表す NODE 構造体になるまで、child が parent から見て左の子か右の子かを判断し、左の子であればビット列の一番左に ‘0’ を、右の子であれば ‘1’ を追加する、を繰り返します。
/* 根の節はparentがNULL */
while(parent != NULL){
/* 親から見て今注目している節が左の子の場合 */
if(parent->left == child){
/* ビット列(value)の一番左へビット0を追加 */
value = value + (0 << bit);
/* 親から見て今注目している節が右の子の場合 */
} else if(parent->right == child){
/* ビット列(value)の一番左へビット1を追加 */
value = value + (1 << bit);
}
/* ビット列のビット数を1増やす */
bit++;
/* 今注目している節の親を、新たな注目節に更新 */
child = parent;
/* 親も親の親に更新 */
parent = parent->parent;
}この繰り返しが完了した時点のビット列が、追加した CODE 構造体の chr に対する符号となりますので、value にビット列の値を、bit にそのビット列のビット数を格納します。
add->value = value;
add->bit = bit;最後に CODE 構造体もリスト構造体として扱うために、リストに追加します。まだ CODE 構造体が一つもない場合と、そうでない場合とで処理が違うので注意してください。
/* CODE構造体がまだ一つもない場合 */
if(code == NULL){
code = add;
top = code;
code->next = NULL;
/* CODE構造体がすでにある場合は最後尾に追加 */
} else {
code->next = add;
code = code->next;
code->next = NULL;
}最後に NODE 構造体のリストを次の NODE 構造体に移動します。前述の通り、NODE 構造体が表す節が葉でなくなった場合に、この makeHuffmanCode 関数は終了します。
スポンサーリンク
データの符号化
データの符号化は encodeFile 関数で行なっています。この関数では主にファイルへのヘッダーの書き込みと、符号化データのファイル出力の2つの処理を行なっています。
ヘッダーの書き込み
最初に行うのがヘッダーの書き込みです。ここでは、どの文字をどの符号に置き換えているかの情報等をヘッダーに格納し、これをファイルに書き込みます。データを復号化するときに、このヘッダーの情報を用いて復号化を行います。
ヘッダーの形式としては、「文字1バイト」、「ビット数1バイト」、「符号4バイト」の計6バイトを1文字の符号の情報を表すデータとし、これを入力ファイルに存在する全ての文字分(つまりハフマン木の葉の数分)ヘッダーに書き込みます。
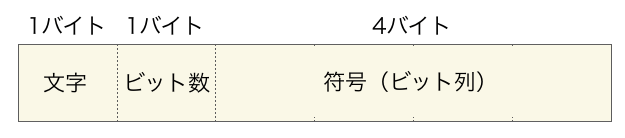
さらに、ヘッダーの終端が分かるように、最後に「終端を表す文字 ‘\0’ 1バイト」、「入力ファイルの文字数4バイト」をファイルに出力します。なので、このプログラムで作成しているヘッダーは下記のような形式になります。

このヘッダーをファイルに書き込んでいるのが encodeFile 関数の前半になります。
まず下記で各文字に対する符号の情報を fwrite 関数を使って書き出し、
/* CODE構造体のリストの先頭から終端まで、
文字の符号化情報をヘッダーとして書きだす */
while(code != NULL){
/* まず文字を書き込む */
fwrite(&(code->chr), sizeof(code->chr), 1, fo);
/* 符号化文字のビット数を書き込む */
fwrite(&(code->bit), sizeof(code->bit), 1, fo);
/* この文字のエンコード結果を書き込む */
fwrite(&(code->value), sizeof(code->value), 1, fo);
headerSize += sizeof(code->chr) + sizeof(code->bit) + sizeof(code->value);
/* 次の文字の符号化情報書き出しに移る */
code = code->next;
}さらに下記で ‘\0’ の文字(terminal には ‘\0’ が格納されている)と、文字数を書き出しています。
fwrite(&terminal, 1, 1, fo);
fwrite(&textlength, sizeof(textlength), 1, fo);符号化データのファイル出力
符号化データの書き込みはちょっと複雑です…。なぜかというとビットデータのファイル書き込みを行う必要があるからです。C言語には標準関数を使ってファイル書き込みできるのはバイト単位のみで、ビット単位の書き込みができる標準関数はありません。なので、ビットデータをバイトに一まとめにし、バイト単位でファイル書き込みを行う必要があります。ここがちょっと複雑なんですよね…。
なので、まずどのようにしてビット列をバイト単位のデータに変換するかについて説明したいと思います。
このプログラムでは、文字に対応する符号ビット列を1ビットずつ、でてきた順にバイトデータの空いてるビットの左側からどんどん足し合わせて行くことでビット列のバイトへの詰め合わせを行ないます。
1バイト分詰められれば、その時点で fputc 関数や fwrite 関数等の標準関数を用いてファイルに1バイト分書き込みを行います。
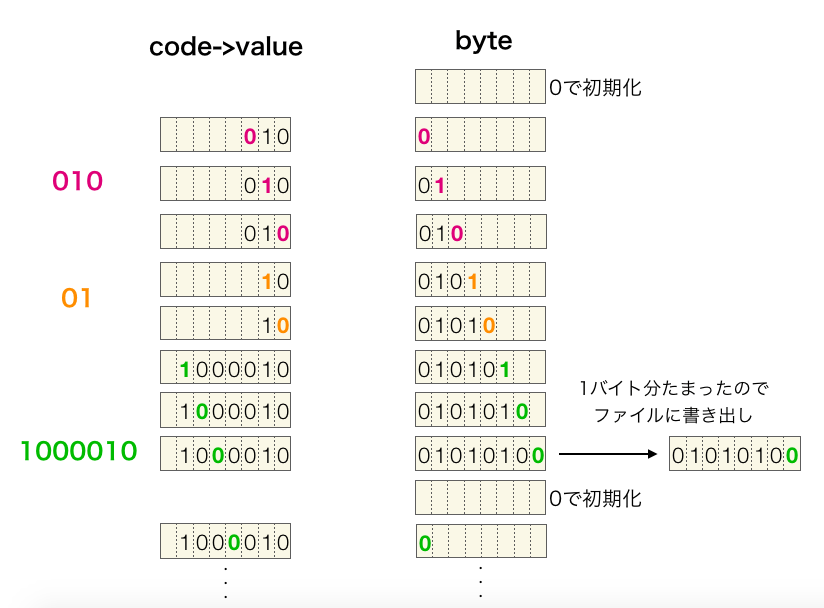
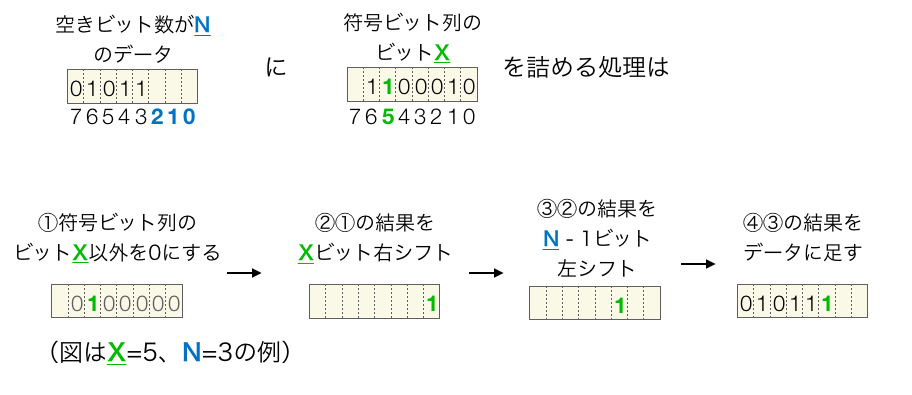
詰め合わせる処理をもう少しプログラム的に説明しておきます。空きビット数がNのデータに符号ビット列のビットXを詰めるためには下記の4つの処理で実行することができます。
①符号ビット列のビットX以外を0にする(ビットXのみを1としたビット列と & をとる)
②①の結果をXビット右シフト
③②の結果をN – 1ビット左シフト
④③の結果をデータに足す
ではプログラムの説明に移ります。
まず下記でファイルから1文字読み込み、その文字に対応する CODE 構造体を取得します。
/* ファイルから1文字ずつ読み込み */
while((chr = fgetc(fi)) != EOF){
/* 読み込んだ文字に対応するCODE構造体を取得 */
code = searchCode(head, chr);続いて下記で符号のビット列の最上位ビットからループを行い、
/* 符号の最上位ビットからバイトデータへ詰め合わせ */
for(i = code->bit - 1; i >= 0; i--){その中で先ほど解説した①から④相当の処理を行います。
/* iビット目が1でそれ以外が0のビット列を作成 */
mask = 1 << i;
/* iビット目以外を0にしたのちiビット分右シフト */
oneBit = (code->value & mask) >> i;
/* バイトデータの空きビット数 - 1分左シフトして足し合わせ */
byte += oneBit << (emptyBits - 1);1 ビット分詰め合わせを行なったので、空きビット数を減らし、空きビット数が0になった場合は 8 ビット分(1 バイト分)のデータが詰め合わせできたということなので、その時点でファイル出力を行います。
/* 空いているビット数を1減らす */
emptyBits--;
/* 空いているビットが0になったらファイルへ書き出し */
if(emptyBits == 0){
fwrite(&byte, 1, 1, fo);
/* ファイルに書き出したので空きビット数を8、
byteを0で初期化 */
emptyBits = 8;
byte = 0;
}これを符号ビット列のビット 0 まで繰り返し、さらにこれらの処理を全文字に対して処理を行うことで、符号化データをファイルに書き出すことができます。
実行方法と実行結果
実行時は引数に入力ファイル名を指定してください。例えば入力ファイル名が「text.txt」で実行ファイル名が「encode.exe」の場合、コマンドラインから実行するのであれば下記のコマンドで実行できます。
./encode.exe text.txt
実行すると、huffman.enc というファイルが出力されます。
入力ファイルに下記の文字列を格納し、(ちなみにこれはシャーロックホームズの緋色の研究の冒頭の英文になります)
IN THE YEAR 1878 I took my degree of Doctor of Medicine of the University of London, and proceeded to Netley to go through the course prescribed for surgeons in the Army. Having completed my studies there, I was duly attached to the Fifth Northumberland Fusiliers as assistant surgeon. The regiment was stationed in India at the time, and before I could join it, the second Afghan war had broken out. On landing at Bombay, I learned that my corps had advanced through the passes, and was already deep in the enemy’s country. I followed, however, with many other officers who were in the same situation as myself, and succeeded in reaching Candahar in safety, where I found my regiment, and at once entered upon my new duties. The campaign brought honours and promotion to many, but for me it had nothing but misfortune and disaster. I was removed from my brigade and attached to the Berkshires, with whom I served at the fatal battle of Maiwand. There I was struck on the shoulder by a Jezail bullet, which shattered the bone and grazed the subclavian artery. I should have fallen into the hands of the murderous Ghazis had it not been for the devotion and courage shown by Murray, my orderly, who threw me across a pack-horse, and succeeded in bringing me safely to the British lines.
このテキストファイルをハフマン符号化した場合、ファイルサイズは下記のようになります。
元データ:1289バイト ハフマン符号化データ:1043バイト
ヘッダーがちょっと手抜きの作りになっていてサイズが大きくなってしまっていますが、それでもサイズ圧縮ができていることが確認できると思います。
符号化した結果を元のテキストファイルに戻すハフマン復号化については下記ページで解説していますので、上手くエンコードできたかどうかを確認したい方はこちらも読んでみてください。
 C言語でハフマン復号化
C言語でハフマン復号化
最後に
軽い気持ちでこのページを作ろうと思ったのですが、思ったよりプログラムや説明が長くなって大作になってしまいました…。説明不十分なところもあるかと思いますので、不明点などあれば気軽にコメントいただけるとありがたいです。
ここに書かれてあるプログラムを研究に使ってもよろしいですか?
本城さん
コメントありがとうございます。
単純なハフマン符号化のプログラムですし、私が考えて作ったものですので、使っていただいても良いです。
ですが、コピペして何か問題が発生した際には、私は一切の責任を負いかねますので、その点だけはご了承下さい。
上手く動かない、こんな感じで変更したい、などあれば、ご相談にはのれると思います。
返信ありがとうございます。
ありがたく使用させていただきます。
本城さん
また何かあればコメントいただければ幸いです。
研究うまくいくこと祈ってます!
文字にハフマン符号を割り当て、その情報をCODE構造体に格納する関数内の、追加したCODEに符号そのものとそのビット数を設定する箇所
add -> value =value
add -> bit = bit
でCODEはvalue,bitという名前のメンバを持っていませんとエラーが出たのですが、対処法はありますか?
平塚さん
コメントありがとうございます!
おそらくですが
・struct code 構造体の定義がうまくいっていない
・typedef struct code CODE; が抜けている
あたりが原因じゃ無いかなぁと思います。
下記部分を再度コピペし直してみればエラー解消されないでしょうか?
返信ありがとうございます。
正しく動作できました!構造体に不備がありました…。
また、よろしくお願いします!
平塚さん
お返事遅れてしまい申し訳ございません。
正しく動作できたようでこちらとしても嬉しいです。
また何かありましたら気軽にコメントいただければと思います!
プログラムを使ったことがないのでどうやれば実際に動かせるのかが分かりません…よろしければどの位置に./encode.exe text.txtを打ち込むべきか教えてもらってもいいでしょうか?
b さん
コメントありがとうございます!
このページで紹介しているプログラムを実行するには下記の手順が必要です。
1. 「プログラムの例」で紹介しているソースコード全体をテキストエディタ等にコピペする
2. encode.c という名前で保存する
3. encode.c を保存したフォルダと同じフォルダに、符号化したい文章を text.txt という名前で保存する
4. ターミナルやコマンドプロントで encode.c や text.c を保存したフォルダに移動する(cd コマンドを利用して)
5. 下記コマンドを実行して encode.exe を生成する
6. 下記コマンドを実行して encode.exe を実行する
5. に出てくる gcc コマンドを実行するためには gcc というコンパイラをインストールしておく必要があります。
もしまだインストールされていないのであれば事前にインストールしておく必要があります。
インストール方法は Google 等で検索すれば簡単に見つかります!ただインストール方法は使用している OS 等によって異なるので注意してください。
例えば MacOSX を使用しているのであれば「MacOS C言語 コンパイラ インストール」などで検索すればすぐ情報見つかると思います!
ご丁寧な対応ありがとうございます。早速試してみます!
bさん
不明点など出てきましたら出来るだけ協力しますので、またコメントいただければと思います!
今後ともよろしくお願いいたします。
掲載されているプログラムではヘッダーサイズのみが出力されていますが、コードを書き換えてどの文字がどのコードに割り当てられているかを出力してみました。
圧縮後の理論値を計算したいのでどの文字が何回出てきたかも出力したいのですが、どこをどのように書き換えれば、割り当てられたコードのほかにそれぞれの文字の出現回数を表示することができますか?
T.H さん
コメントありがとうございます!
NODE構造体ではfreqメンバに文字の出現回数を格納するようにしています。なので、この値を表示してやれば出現回数自体は表示できます。
ただ符号のビット長と一緒に出現回数を表示したいという要望だと思いますので、もうちょっと変更してやった方が良いかもしれません。
下記はその変更の一例になります。
1.
CODE構造体にfreqメンバを追加2.
makeHuffmanCode関数でCODE構造体の設定をしている箇所でfreqを設定する3.
encodeFile関数でヘッダーサイズを表示している箇所の後でfreq等の値を表示もし上手く動かない、もっと違うタイミングで表示したいなどありましたら、お手数ですがまたコメントいただければと思います。
ありがとうございます。正しく出力できました。
出現回数と同じところに、codeも出力したいのですが、変更箇所を教えていただけますか?
T.H さん
コメントありがとうございます。
上記のコメント返信の、3. の
for文を下記のように変更してみてはどうでしょう?各文字を符号化した結果が下記のように表示されるようになります。
ありがとうございました!希望通りの出力ができました!
またよろしくお願いいたします。
T.H さん
ちゃんと動作させられたようで良かったです!
また何かあれば気軽にコメントいただければと思います。よろしくお願いいたします。
何度もごめんなさい。
daeuさんの返信の、I : bit = 7 freq = 12 code(16) = 0x66 code(2) = 1100110 はcode(16)がASCIIコードの出力だと思うんですか、IのASCIIコードを調べたら0x49になっていました。
これはASCIIコードではないのでしょうか?
T.H さん
説明不足で申し訳ございません。
code(2) が符号化したビット列で、code(16) がそのビット列を16進数で表したものはなります。
ですので、アスキーコードではなく、符号化結果と捉えて読んでみてください!