

下のページでハフマン符号化のC言語プログラムについて紹介しました。
 C言語でハフマン符号化
C言語でハフマン符号化
このページではハフマン符号化したデータを元のデータに戻すハフマン復号化についての解説と、そのプログラムの紹介を行いたいと思います。
ハフマン復号化の概要
ハフマン復号化は、ハフマン符号化されたデータを元に戻す処理です。下記の2つの処理で復号化を行います。
符号化情報の取得
まずハフマン符号化をどのようにして行ったか、つまり、どの文字をどの符号に置き換えたかの情報が必要です。その符号化の情報の取得を行います。
例えばですが、私の符号化のプログラムでは、符号化ファイルのヘッダーにその情報を格納していますので、ヘッダーをまず読み込んで、符号化情報の取得を行います。
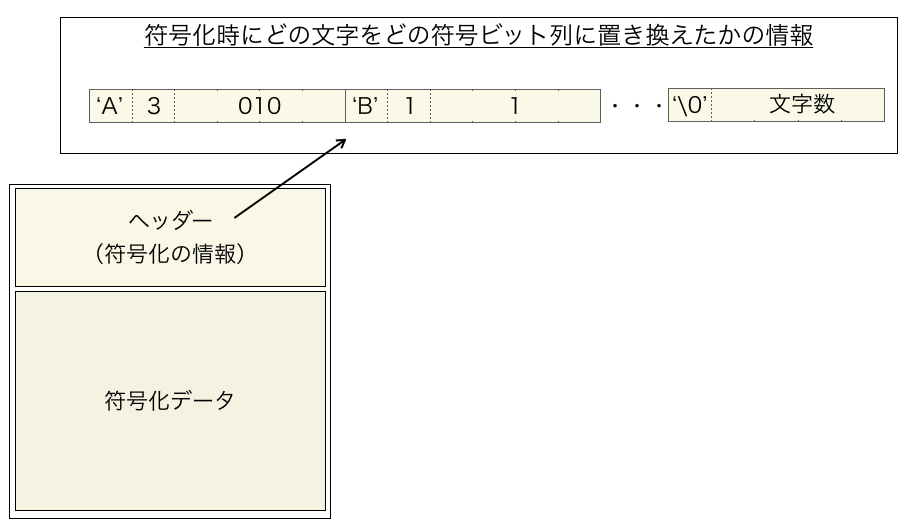
スポンサーリンク
データの復号化
データの復号化では、入力ファイルを読み込んで符号ビット列を取得し、そのビット列を符号化情報に基づいて文字に置き換えていきます。
私の符号化プログラムでは、入力ファイルに現れた文字の符号ビット列を、現れた順に左側のビット(最上位ビット)から詰めてファイル出力しています。

ですので、復号化においては、符号データ部分を前方から読み進め、符号ビット列となるビット列を見つけたら随時、そのビット列に対応する文字に置き換えて、それを出力ファイルに書き出す処理を行います。
プログラムの例
こちらがハフマン符号化されたデータを復号するプログラムになります。
#include <stdio.h>
#include <stdlib.h>
typedef struct code CODE;
/* 符号化情報を格納する構造体 */
struct code {
char chr;
int value;
char bit;
CODE *next;
};
/* CODE構造体を全て削除する関数 */
void freeCode(CODE *code){
CODE *next;
while(code != NULL){
next = code->next;
free(code);
code = next;
}
}
/* 入力されたvalueとbit数に対応する
CODE構造体を探索する関数 */
CODE *searchCode(CODE *head, int value, char bit){
while(head != NULL){
if(head->value == value && head->bit == bit){
return head;
}
head = head->next;
}
return NULL;
}
/* ハフマン符号化されたinnameファイルを
復号化してoutnameに書き出す関数 */
int decodeFile(char *outname, char *inname){
FILE *fi = NULL;
FILE *fo = NULL;
CODE *head = NULL;
CODE *tail = NULL;
CODE *add = NULL;
CODE *code = NULL;
unsigned int headersize;
unsigned int textlength;
int bits;
char bitNum;
int oneBit;
char chr;
int mask;
int i;
/* 入力ファイルを開く */
fi = fopen(inname, "rb");
if(fi == NULL){
printf("%s open error\n", inname);
return -1;
}
headersize = 0;
while(1){
/* まず文字情報を読み込む */
fread(&(chr), sizeof(chr), 1, fi);
/* 符号化データの終端を表す '\0'であった場合
ヘッダー読み込みを終了 */
if(chr == '\0') break;
/* CODE構造体を追加 */
add = (CODE*)malloc(sizeof(CODE));
if(add == NULL){
printf("malloc error\n");
fclose(fi);
return -1;
}
add->next = NULL;
/* 文字情報に読み込んだ文字をセット */
add->chr = chr;
/* 符号化文字のビット数を読み込む */
fread(&(add->bit), sizeof(add->bit), 1, fi);
/* この文字のエンコード結果を読み込む */
fread(&(add->value), sizeof(add->value), 1, fi);
headersize += sizeof(add->chr) + sizeof(add->bit) + sizeof(add->value);
printf("chr = %c, bit = %d, value = %x\n", add->chr, add->bit, add->value);
if(head == NULL){
/* CODE構造体が一つもない場合はリストの先頭とする */
head = add;
tail = head;
} else {
/* CODE構造体がすでにある場合はリストの最後尾に追加 */
tail->next = add;
tail = add;
}
}
/* ヘッダーの '\0'にある元データの文字数を取得 */
if(chr == '\0'){
fread(&textlength, sizeof(textlength), 1, fi);
}
printf("headrsize = %lu\n", headersize + 1 + sizeof(textlength));
/* 出力ファイルを開く */
fo = fopen(outname, "w");
if(fo == NULL){
printf("%s open error\n", outname);
fclose(fi);
freeCode(head);
return -1;
}
/* ビット列とビット数を0で初期化 */
bits = 0;
bitNum = 0;
while(textlength > 0){
/* ファイルから1バイト分読み込み */
chr = fgetc(fi);
/* chrの最上位ビット7からビット0までループ */
for(i = 7; i >= 0; i--){
/* ビットiだけ立てたビット列を作成 */
mask = 1 << i;
/* 論理積とシフト演算によりchrのビットiの値を取得 */
oneBit = (chr & mask) >> i;
/* ビット列を1ビット左シフトして右側に1ビット空きを作る */
bits = bits << 1;
/* ビット列の右端ビットにビットiの値を詰め合わせる */
bits += oneBit;
/* 上記でビット数が増えたのでbitNumを増加 */
bitNum++;
/* bitsをvalueとし、bitNumをbitとする
CODE構造体を探索 */
code = searchCode(head, bits, bitNum);
/* そのようなCODE構造体がある場合は、
そのCODE構造体のchrをファイルへ書き出し */
if(code != NULL){
fputc(code->chr, fo);
/* 書き出したので符号ビット列bitsを0に、
ビット数bitNumを0にセット */
bits = 0;
bitNum = 0;
/* 1文字書き込んだので残り文字数を1減らす */
textlength--;
/* 残り文字数が0になったら終了 */
if(textlength <= 0){
break;
}
}
}
}
/* ファイルをクローズ */
fclose(fo);
fclose(fi);
/* CODE構造体を削除 */
freeCode(head);
return 0;
}
int main(int argc, char* argv[]){
char outname[256];
if(argc != 2){
printf("引数に入力ファイル名を指定してください\n");
return -1;
}
sprintf(outname, "decode.txt");
if(decodeFile(outname, argv[1]) != 0){
printf("%s decode erorr\n", argv[1]);
}
return 0;
}プログラムの解説
それではプログラムの解説をしていきます。
スポンサーリンク
構造体
構造体として符号情報を格納するCODE構造体を定義しています。
CODE構造体
CODE構造体は各文字の符号情報を格納するデータです。
- chr:文字
- value:符号(ビット列)
- bit:符号のビット数
- next:次の符号情報へのポインタ
こちらも next を用意し、リスト構造的に符号情報を管理します。
符号化情報の取得
符号化情報の取得はdecodeFile関数の前半部分で行なっています。
符号化のページで解説している通り、ヘッダーには「文字1バイト」「ビット数1バイト」「符号ビット列4バイト」の6バイトが入力ファイルに現れる文字の数だけ格納されています。
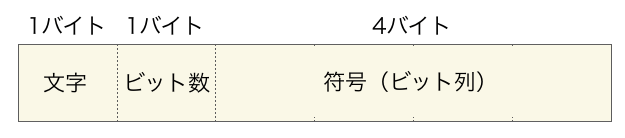
さらに、文字が ‘\0′ の場合はヘッダーの終了を表しており、’\0’ の次にテキストの文字数が4バイト分格納されています。
なので、プログラムでは下記でまず最初の1バイト分読み取り、それが ‘\0’ の場合はヘッダーの読み取りを終わり、それ以外の場合は次のビット数の1バイトと符号の4バイトを読み込み、これらの3つの情報をCODE構造体に格納しています。
/* まず文字情報を読み込む */
fread(&(chr), sizeof(chr), 1, fi);
/* 符号化データの終端を表す '\0'であった場合
ヘッダー読み込みを終了 */
if(chr == '\0') break;
/* CODE構造体を追加 */
add = (CODE*)malloc(sizeof(CODE));
if(add == NULL){
printf("malloc error\n");
fclose(fi);
return -1;
}
add->next = NULL;
/* 文字情報に読み込んだ文字をセット */
add->chr = chr;
/* 符号化文字のビット数を読み込む */
fread(&(add->bit), sizeof(add->bit), 1, fi);
/* この文字のエンコード結果を読み込む */
fread(&(add->value), sizeof(add->value), 1, fi);さらにこのCODE構造体をリストで管理するために下記の処理を行なっています。リストの先頭を表すポインタ head がNULLということはCODE構造体がまだ一つもないということなので、head と 最後尾を指す tail に追加したCODE構造体を指させます。NULLでなければすでにCODE構造体があるのであれば最後尾である tail の次を表す next メンバに追加したCODE構造体を指させます。
if(head == NULL){
/* CODE構造体が一つもない場合はリストの先頭とする */
head = add;
tail = head;
} else {
/* CODE構造体がすでにある場合はリストの最後尾に追加 */
tail->next = add;
tail = add;
}文字が ‘\0’ であればヘッダーの終わりということですので、while文を break で抜け出し、最後にテキストの長さ(文字数)を取得します。
/* ヘッダーの '\0'にある元データの文字数を取得 */
if(chr == '\0'){
fread(&textlength, sizeof(textlength), 1, fi);
}スポンサーリンク
データの復号化
データの復号化はdecodeFile関数の後半で行っています。
まずビット列を格納する bits とビット列のビット数を格納する bitNum を0で初期化します。
bits = 0;
bitNum = 0;続いて下記で、ヘッダーで読み込んだテキストの文字数全てをファイル出力するまで復号化とファイル出力の繰り返しを行います。
while(textlength > 0){復号化処理では、まずファイルから1バイト分データを読み込み
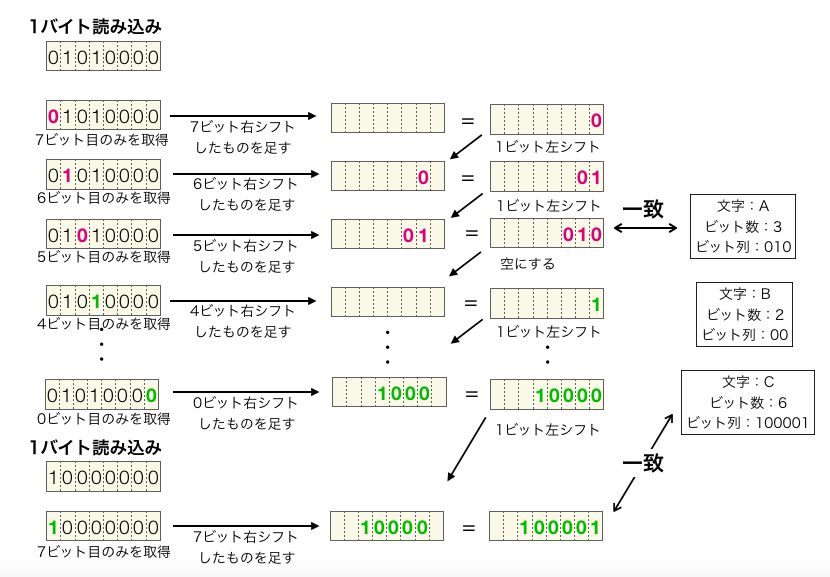
chr = fgetc(fi);続いて下記のfor文でループを行い、読み込んだデータを最上位ビット(ビット7)から1ビットずつ復号化を行います。
for(i = 7; i >= 0; i--){このループの中では、まず chr のビット i の値だけを取得するために、下記でビット i だけ1となる値を作成します。
mask = 1 << i;そして、下記で、この chr と mask の論理積を取得し、i ビット分だけ右シフトを行います。これにより、chr のビット i の値が ビット1に格納された値を取得することができます。
oneBit = (chr & mask) >> i;さらに、ビット列の最下位ビット(ビット1)に空きを作るため、bits を 1ビット分左シフトします。
bits = bits << 1;続いて、下記で bits と oneBit の値を足し合わせ、bits に格納します。
bits += oneBit;bits のビット数が1増えるので、bitNum の値を1増やします。
bitNum++;そして、この時点でsearchCode関数を実行して、value の値が bits かつ bit の値が bitNum となるCODE構造体が存在するかどうかを確認します。
code = searchCode(head, bits, bitNum);searchCode関数は、value の値が bits かつ bit の値が bitNum となるCODE構造体が存在する場合に、そのCODE構造体へのポインタを返却します。なので、searchCode関数の返却値である code がNULL以外の場合は、bits を復号化して文字を取得することが可能ですので、その文字である code->chr をfputc関数でファイル出力します。
続いて新しいビット列を作っていくために、下記で bits と bitNum を0に設定します。
bits = 0;
bitNum = 0;また、文字を1文字出力したので、textlength を1減らします。この時点で textlength が0になった場合は、もう出力すべき文字がないということなのでfor文を break で終了します。
textlength--;
/* 残り文字数が0になったら終了 */
if(textlength <= 0){
break;
}まだ textlength が1以上であれば、残りのビットを処理し、さらにファイルから次の1バイトの読み込んで、同様の処理を繰り返します。
while文が終了した時点で、全符号ビット列を復号した事になります。
ビット演算のあたりは文字だけだとわかりにくいかもしれませんので、図でも示しておきます。
スポンサーリンク
実行方法と実行結果
実行時は引数に入力ファイル名を指定してください。例えば入力ファイル名が「huffman.enc」で実行ファイル名が「decode.exe」の場合、コマンドラインから実行するのであれば下記のコマンドで実行できます。
./decode.exe huffman.enc実行すると、入力ファイルを復号化した結果が「decode.txt」という名前のファイルに出力されます。
下記ページで符号化したファイルを入力すると、符号化前のテキストファイルと同じ結果が得られましたので、おそらく上手く動作してくれるのではないかと思っています。おかしい点などありましたら指摘していただけると助かります。
C言語でハフマン符号化
最後に
思ったよりも手こずりました…。やっぱりビットの扱いは難しいですね。何度も試行錯誤してやっとできたっていう感じです。しかも説明するのが難しい…。一応図をつけて分かりやすくしたつもりですが、不明点などあれば問い合わせ等していただければ回答します。
符号化したファイルを正しく復号化することに成功したのですが、空白を表す出力結果で、
chr = , bit = 2, value = 0 となり符号が0ならビットが1ではないのか?と思ったのですが、なぜ2ビットになっているのでしょうか?
その他の符号も16進数から2進数に直したところ符号より1ビット大きい値が出力されていました。
初歩的な質問で申し訳ありません。よろしくお願いします。
T.H さん
コメントありがとうございます!
ごもっともな疑問だと思いました!ちょっと分かりにい出力になってましたね…。
結論としては、ビット数が少ないのはビットの前方側に “0” があるからです。
例えば空白文字の符号長は 2 bit なので、符号は “0” ではなく “00” として扱っています。
単純に value の値は4バイトのデータを 16 進数で表示しているだけなので、このビット長を考慮して表示できていないんですよね…。
例えば chr と bit と value を表示している printf のところを下記のように変更すれば、符号そのものを表示することができます。
このように変更すれば、例えば空白文字の符号情報は下記のように表示されるようになります。
code の出力が符号そのもので、ビット長を考慮した表示になります。
おそらくこっちの結果だとしっくりくるのではないかと思います。
是非時間のある時にでも試してみてください!
返信ありがとうございます。教えていただいたようにコードを入力し、出力してみた結果
chr = A, bit = 8, value = ba, code = 01011101 と表示されました。
value = ba 2進数に直したところ10111010となりコードの値と逆の値になるのですが、これはシフトが原因で反転しているのでしょうか?
T.H さん
ご返信ありがとうございます。
そして、大変失礼いたしました。記入したソースコードが間違っていました…。
ご指摘の通り、ビット列の表示順が逆になってしまっています。
符号データの表示部分を下記のように変更すればビット列の表示順が直ると思います。
大変お手数をおかけしますが、下記で試してみていただけると幸いです。