

令和元年度秋期午後のC言語問題である問9の私の解き方・考え方について解説していきます。
問題
IPAの公式サイトで公開されています。このページでは問9についての解説を行います。
https://www.jitec.ipa.go.jp/1_04hanni_sukiru/mondai_kaitou_2019h31_2/2019r01a_fe_pm_qs.pdf
問題の概要
ファイルを読み込んで、そのファイルのデータを1バイトずつ文字および16進数で表示するプログラムに関する問題です。
プログラムの動きのイメージとしては図2が分かりやすいと思います。

ファイルのデータは3行で表示され、1行目はそのデータを文字で表現したもの、2行目はそのデータを16進数で表現した結果の上位4ビット、3行目はそのデータを16進数で表現した結果の下位4ビットがそれぞれ表示されます。
またプログラムには from と to を指定する事が可能であり、読み込んだデータの from で指定したバイトから to で指定したバイトまでが上記のように3行で表示されます。
ただし to には負の値も入力可能で、その場合は from で指定したバイトからファイルの末尾までが表示されることになります。
スポンサーリンク
設問1
設問1はプログラムの穴埋め問題です。このプログラムは大きく3つに分割する事ができます。
まず1つ目は下記の部分になります。
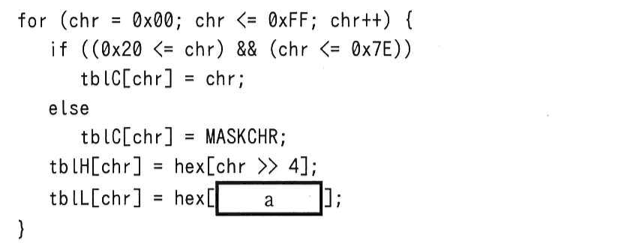
この部分では読み込んだ1バイトのデータ(0x00 〜 0xFF)に応じて表示する「文字」と「16進数の上位4ビット」と「16進数の下位4ビット」をあらかじめ準備している処理を行っています。
tblC はアスキーコードで文字に割り当てられている “0x20” から “0x7E” のみその値が格納され、それ以外は “.” が格納されていますので、 tblC には各バイトデータに対する文字が格納されていると考えられます。
また tblH には chr が右に4ビットシフトされた値を “0” から “F” に変換したものが格納されています。ある値を右に4ビットシフトすると、上位の4ビットが下位4ビットに移動し、元々あった下位4ビットは捨てられることになります。ですので、tblH には16進数の上位4ビット(に対応する英数字)が格納されていると考えられます。
したがって tblL には残りの16進数の下位4ビットが格納されていると考えられます。元々の値 chr の下位4ビットは、上位4ビットが全て “0” で下位4ビットが全て “1” の値と chr との「&」を取る事で取得する事ができます。
上位4ビットが全て “0” で下位4ビットが全て “1” である値は2進数で表すと「00001111」になりますが、これを16進数に変換すると「0x0F」となります。したがって、この「0x0F」と chr とで & 演算を行う事で下位4ビットが取得できます。つまり [ a ] の答えは「ア」となります。
プログラムの2つ目の部分は下記の部分です。

ここはデータを読み込み、読み込んだデータを表示する部分になります。
この部分のプログラムの穴埋めの一つ目である [ b ] は下記のデータの読み込みを継続する条件の穴埋めになります。
while(((chr = fgetc(infile)) != EOF)
[ b1 ] ((to < 0) [ b2 ] (cnt <= to))) {
cnt++;cnt は初期値が 0 で、fgetc() するたびに1増える変数なので、読み込んだバイト数をカウントする変数であると考えられます。
また引数 from と to に対してファイルのデータ表示をどこまで継続するかは下記に記載されています。

この設問に関しては [ b ] の選択肢である「ア」から「エ」に関して試し、プログラムの仕様を満たせるかどうかを確認するのが確実だと思います。
まず [ b1 ] と [ b2 ] の両方が「&&」の「ア」について考えてみましょう。
while(((chr = fgetc(infile)) != EOF)
&& ((to < 0) && (cnt <= to))) {
cnt++;to が 0 以上の場合、(to < 0) が常に不成立になるため、常に while の中の条件は不成立になります。つまり1度もデータの読み込みと表示が行われませんので、to ≧ 0 の場合が仕様を満たせません。したがって「ア」は間違いです。
続いて[ b1 ] と [ b2 ] の両方が「||」の「エ」について考えてみましょう。
while(((chr = fgetc(infile)) != EOF)
|| ((to < 0) || (cnt <= to))) {
cnt++;to が 0 未満の場合、(to < 0) が常に成立になるため、while の中の条件も常に成立になります。つまり、ファイルの終端まで読み込み終わってもなおデータの読み込みと表示が行われてしまうことになり、to < 0 の場合の仕様が満たせません。したがって「エ」は間違いです。
次は [ b1 ] が「||」で [ b2 ] が「&&」である「ウ」について考えてみます。
while(((chr = fgetc(infile)) != EOF)
|| ((to < 0) && (cnt <= to))) {
cnt++;この場合、「||」の前後の条件式のどちらか一方でも成立すればファイルのデータ読み込みと表示が継続されることになります。つまり、ファイルが終端まで行くまで必ずファイルのデータ読み込みと表示が継続されることになり、to ≧ の場合の仕様が満たせません。したがって「ウ」は間違いです。
最後に [ b1 ] が「&&」で [ b2 ] が「||」である「イ」について確認します。
while(((chr = fgetc(infile)) != EOF)
&& ((to < 0) || (cnt <= to))) {
cnt++;to < 0 の場合は、「&&」以降の条件式は常に成立しますので、ファイルの終端まで読み込んだと時に、fgetc() から EOF が返却されて while 文を抜け出すことになります。
また to ≧ 0 の場合は、ファイルの終端まで読み込んだ場合もしくは cnt が to を超えた場合(つまり to で指定されたバイト位置までのデータ読み込み・表示が完了した場合)に while 文を抜け出すことになります。
さらに下記によれば、「to < ファイルサイズ」が成立しますので、必ず to で指定されたバイト数のデータ読み込みと表示が完了した場合に while 文を抜け出すことになり、to ≧ 0 の場合の仕様も満たす事ができます。

したがって [ b ] の答えは「イ」となります。
続いてプログラムでは下記の赤枠部分で読み込んだデータ chr の値に基づいて表示するデータが各配列に格納されていっています。
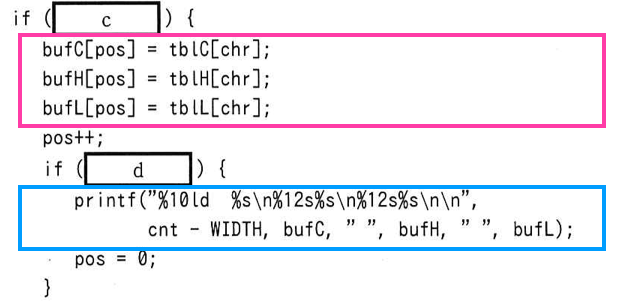
プログラムの仕様的に、実際の表示は60バイトずつ一気に行われることになっていますので、赤枠部分でデータ表示の準備を行い、青枠部分で60バイト分のデータを表示している処理を行なっていると考えられます。
さて [ c ] に何が入るかを考えていきましょう。[ c ] はデータの表示(データの表示準備)を行う条件が入ると考えられます。データの表示は、from で指定したバイト位置からですので、ファイルの読み込みがそのバイト位置まで行われているかをここで判断をしているようです。[ c ] の選択肢的にもそんな感じですね。
この [ c ] を回答するときに注意すべきポイントはバイト位置のカウントの仕方です。下記に記載されている通り、バイト位置はファイルの先頭のバイトを0としてカウントすることになっています。

ですので、ファイルを先頭から1バイト読み込んだ時に得られるデータのバイト位置は0になります。同様にファイルを先頭から10バイト読み込んだときに得られるデータのバイト位置は9になります。つまり、読み込んだサイズの値に対してバイト位置はー1された値になると言うことです。
なので、バイト位置 from のデータから表示を開始するのであれば from + 1 バイト読み込んだ時からデータの表示(表示するための準備)を開始する必要があります。
読み込んだバイト数は cnt に格納されていますので、データの表示を開始するのは cnt が from + 1 になったときであり、これを判断するための条件は cnt > from もしくは cnt ≧ from + 1 などになります。したがって [ c ] の答えは「ア」となります。
[ d ] は実際にデータの表示を行う条件を問う問題です。下記に記載のようにデータの表示は60バイトずつ行われます。pos に注目すると、pos はデータの表示準備(bufC, bufH, bufL へのデータ格納)を行うたびに “1” 増え、データの表示が行われた時に “0” にリセットされる変数になっています。つまり、pos には表示がまだ行われていないデータのバイト数が格納されていると考えられます。
さらに WIDTH は 60 として定義されていますので、pos が WIDTH になった時に実際に表示を行う必要があります。したがって [ d ] には pos が WIDTH になったとかどうかを判断するための条件が格納されていると考えられ、選択肢的に [ d ] の答えは「オ」となります。
設問2
設問2は下記の [ケース1] と [ケース2] の場合の最終行の表示結果を問う問題です。最終行の表示はプログラムの最後の部分である下記の赤枠部分で行われています。

つまり、chr が EOF であるかどうかと、from と cnt の値によって表示結果が決定されます。
[ e ] は設問の文章の通り、「ファイルサイズ = 100、from = 99、to = 99」の場合の最終行の表示内容が入ります。この場合に、100バイト目を読み込むために下記が実行された時、どのような動きになるかを考えてみましょう。while(((chr = fgetc(infile)) != EOF)
&& ((to < 0) || (cnt <= to))) {
cnt++;100バイト目を読み込む時には、読み込んだバイト数が格納される cnt には “99” が格納されていることになりますので、(cnt <= to) は成立します。さらにファイルサイズは100バイトですので、100バイト目に対する fgetc() も EOF 以外が返却されますので、ループが継続されることになります。ですので、cnt++ も実行され、cnt は “100” になります。
次のループは (cnt <= to) も不成立ですし、fgetc() ではファイルサイズを超える101バイト目を読み込もうとして EOF が返却されますので、ループは終了です。さらに chr には最後の fgetc() の返却値である EOF が格納されます。
そのまま chr と cnt への値の代入が行われることなく、下記の赤枠部分まで処理が実行されますので、この赤枠部分の if 文は成立し、さらに cnt – from は “1” となります。
したがって、[ケース1] の最終行の表示内容が入る [ e ] の答えは「オ」となります。
また [ f ] は設問の文章の通り、「ファイルサイズ = 0、from = 0、to = 0」の場合の最終行の表示内容が入ります。同様に、この場合にファイルの最初の1バイト目を読み込むために下記が実行された時、どのような動きになるかを考えてみましょう。
while(((chr = fgetc(infile)) != EOF)
&& ((to < 0) || (cnt <= to))) {
cnt++;1バイト目を読み込む時には、読み込んだバイト数が格納される cnt には初期値の “0” が格納されていることになりますので、(cnt <= to) は成立します。しかし、ファイルサイズが0バイトなので、最初の fgetc() でいきなり EOF が返却されます。したがって chr には EOF が格納されますし、ループ処理も1度も行われずに終了することになります。
つまり chr には EOF が、cnt は “0” が格納された状態で、下記の赤枠部分まで処理が実行されます。
chr には EOF が格納されているため、この赤枠部分の if 文は成立し、さらに cnt – from は “0” となります。したがって、[ケース2] の最終行の表示内容が入る [ f ] の答えは「ウ」となります。
解いてみた感想
プログラムとしては分かりやすく、問題としても解きやすい設問が多かったと思います。ただ特に [ c ] に関してはプログラムをしっかり読み込んでいないとバイト位置が0からカウントされる事が分からず、間違えてしまう人も多かった問題ではないかと思います。
ポイントになりそうなところは線を引くなどして後からすぐ見返せるようにして問題を読んでいくのが良いと思います。
★オススメページ★
下記ページから他の回の解説もたどれます。他の回のC言語問題の解き方がわからない場合は是非読んでみてください!
 基本情報技術者試験 午後問題「C言語」過去問の解き方 解説 まとめ
基本情報技術者試験 午後問題「C言語」過去問の解き方 解説 まとめ
本ページの図・プログラム・問題文について
図やプログラム、問題文はIPA公開の過去問題から引用しています。また図やプログラムに関しては説明に必要な部分に関してのみ加工して使用させていただいております。
出典:令和元年度 秋期 基本情報技術者試験(FE)試験区分 午後 問9
