

平成31年度春期午後のアルゴリズム問題である問8の私の解き方・考え方について解説していきます。
問題
IPAの公式サイトで公開されています。このページでは問8についての解説を行います。
https://www.jitec.ipa.go.jp/1_04hanni_sukiru/mondai_kaitou_2019h31_1/2019h31h_fe_pm_qs.pdf
問題の概要
ハフマン符号化に関する問題です。ハフマン符号化では例えば文章に出現する文字の多いものから順に、短いビット列を割り当てていく符号化になります。これによりデータを圧縮することが可能です。ハフマン符号化を既に知っている人にとってはとっつきやすい問題だったかもしれないですね。
具体的にどうやって圧縮を行うかは問題中に記載してくれていますのでここでは省略します。
問題としては、設問1はハフマン符号化のアルゴリズムの理解を確認するもの、設問2はハフマン木作成に関するもの、設問3はハフマン木を用いた符号化に関するものになっています。
スポンサーリンク
設問1
設問1はハフマン符号化のアルゴリズムの理解の確認です。設問1よりも前の文章にハフマン符号化のアルゴリズムについて詳しく書いてあるので、これを読みながらハフマン木を実際に作成してみれば解ける問題だと思います。
実際にハフマン木を作ってみましょう!問題に記載されているハフマン木の作成手順に下記の記載があります。

さらに、設問1で与えられた文字列が”ABBBBBBBCCCDD”なので、①と②により下記のような配列が作れます。
手順①②実行後

要素番号は一番左が0です。なので配列の要素番号0には「1」が格納されており、要素番号3には「2」が格納されています。
続いて次の手順③を行います。

ポイントは節の値の小さい順に節を2つ選択するところですね。さらに値が同じものがある場合は要素番号が小さい方が先に選択されます。この③を一度実行すると下記のようになります。
手順③ 1回目実行後
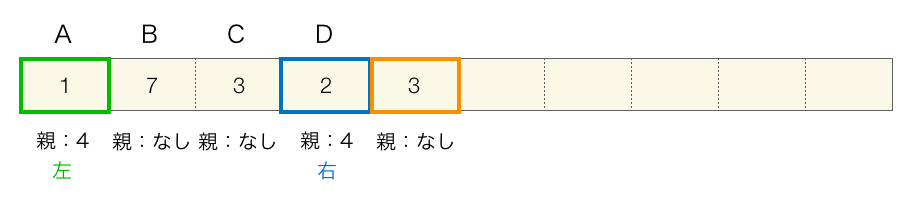
分かりやすいように、1つ目に選択した節(要素)を緑枠で囲い、2つ目に選択した節を青枠で囲んでいます。さらに、追加した節を表す要素はオレンジ枠で囲っています。つまり、オレンジ枠で囲った節の左側の子が緑枠の節で、右側の子が青枠の節となります。
さらに具体的にいうと、要素番号0と要素番号3の値を足した値が配列の要素番号4に格納され、要素番号4が要素番号0と要素番号3の親となります。親の左側の子は要素番号0の節が、親の右側には要素番号3の節となります。
これで手順③の1度目の実行は完了です。
下記の手順④によると手順③を親が作成されていない節が一つになるまで繰り返せということですので、言われた通りに繰り返します。
![]()
手順③ 2回目実行後
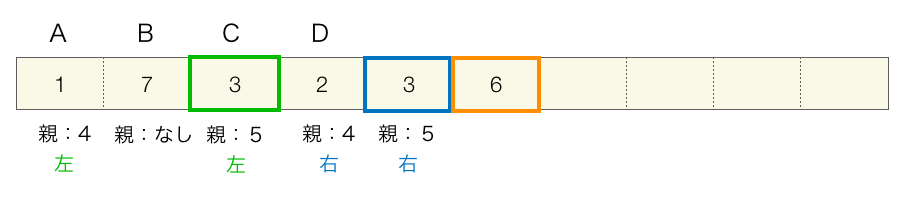
1回目の実行とほとんどやることは同じですが、今度は同じ値がありますので、要素番号が小さい方のものが最初に選択され、左側の子になります。
手順③ 3回目実行後
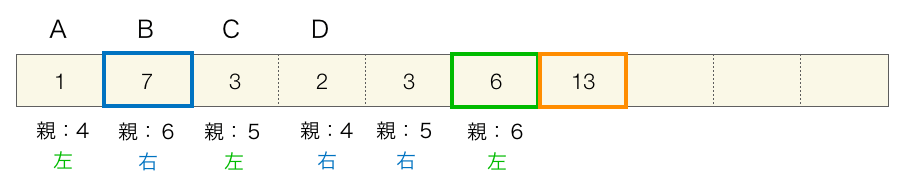
この時点で親が作成されていない節が1つになりますので手順④が終了します。これでハフマン木の作成は完了です。この配列の親の要素番号を辿って木の形に構成すると下のようになります。丸が各節を表し、中に要素番号を記載しています。
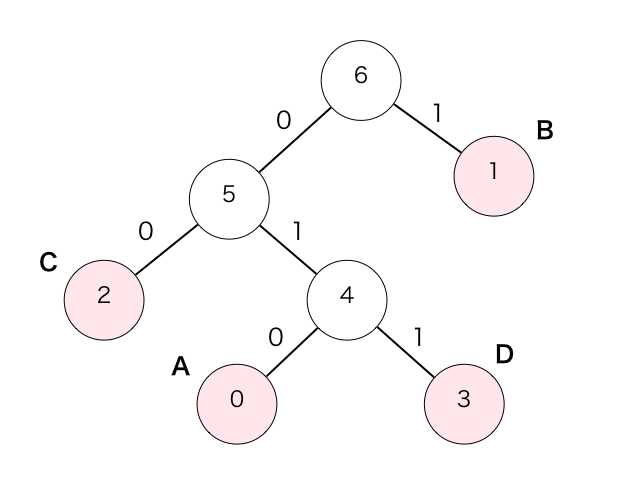
文字”A”〜”D”の符号化結果は上記の木を根からその文字の節まで辿ることで取得できます。
例えばAの場合は下記のように辿れるので「010」となります。
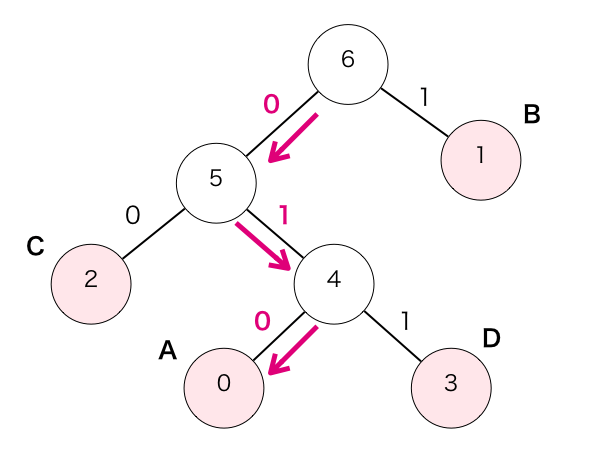
同様にして他の文字も符号化結果を取得すると下記のようになります。
- A : 010
- B : 1
- C : 00
- D : 011
これが設問1の[ a ]の答えとなります。設問1の[ a ]の正解はアです。
[ b ]に関しては、ハフマン木による符号化を行うと、各文字を2ビットで表した時に比べてサイズがどれほど変わるかを問う問題です。実際に文字列”ABBBBBBBCCCDD”をハフマン符号化すると”0101111111000000011011″のビット列になります。これは各文字をハフマン符号化結果に置き換えてやれば取得できます。例えば”A”は”010″に、”B”は”1″に置き換えてやれば上記のビット列となります。このビット列の長さは22であり、各文字を2ビットで表した場合のビット長は13文字 × 2ビットで26です。これを問題の先に当てはめて計算すると、0.85となります。ですので[ b ]の答えは0.85のイとなります。
設問2
設問2はハフマン木作成のプログラムの穴埋め問題です。
まずどういうプログラムであるかをじっくり読みましょう。また副プログラム Huffman はハフマン木を作成プログラムですので、問題の頭の方に記載されていたハフマン木の作成手順①〜④と照らし合わせて考えると分かりやすいと思います。
イメージ的には、副プログラム Huffman とハフマン木の作成手順とは下記のような関係にあります。
副プログラム Huffman にはハフマン木の作成手順①と②が実行された後の結果が入力される
副プログラム Huffman の下記の囲った部分がハフマン木の作成手順③に相当する
副プログラム SortNode がハフマン木の作成手順③の下記の下線部分を実行する

残った副プログラム Huffman の下記の囲った部分がハフマン木の作成手順④に相当する
![]()
最後は予測ですが、[ c ]の左側には下記の記号がありますので、繰り返しを行う条件を埋める必要があると考えるのが自然だと思います。

親が作成されていない節が1つになるまで繰り返す(つまり1つになったら終了する)とのことですので[ c ]に入る繰り返し条件は「親が作成されていない節が2つ以上」となります。さらに SortNode の説明に下記の記載があります。

これより、親が作成されていない節の数は nsize に格納されていることが分かります。したがって、「親が作成されていない節が2つ以上」は「nsize ≧ 2」で判断でき、[ c ]の答えはウとなります。
[ d ]は副プログラム SortNode の穴埋めになります。下記の通り行番号19〜24は親が作成されていない要素番号を抽出する処理が行われます。
行番号21では Sort 関数に渡す配列に要素番号を格納し、行番号22では要素番号の数をカウントアップして nsize に格納しています。これらの処理は、親が作成されている要素に対して実行してしまうと、親が作成された要素を含んだ node 配列を Sort に渡してしまいますし、nsize には親が作成されている要素を含んだ要素数になってしまいますので、SortNode の説明と話が合いません。
そのため、行番号20の条件には「要素番号 i の節が親を持たないこと」が入ると考えられます。さらに、[プログラム1の説明]より、parent 配列の全要素は”-1″で初期化されること、[プログラム1]の行番号11と12より parent 配列には親が作成されないと値が格納されないことが分かります。なので、要素番号 i が親を持たない場合、parent[i] は”-1″のままとなります。
そのため「要素番号 i の節が親を持たないこと」は 「parent[i] が “0”未満であること」で判断することが可能です。したがって[ d ]の答えはエとなります。
設問3
設問3はハフマン木を用いた符号化に関する問題です。
副プログラム Encode の中で第一引数を parent[k]にして Encode を再帰呼び出しする事で、葉から根に辿る処理が実現されています。

例えば設問1で書いたハフマン木を用いて k を 0 とした場合は下記のように辿ることになります。
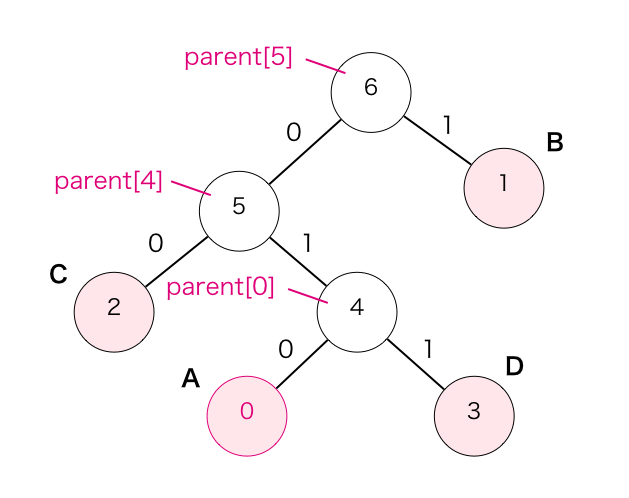
根は親を持たないため、根に辿り着いたかどうかは、parent[k] の値で判断できます。つまり、parent[k] が “-1” でない限り Encode の再帰呼び出しを実行する必要があります。従って[ e ]はオの「parent[k] ≧ 0」となります。
さらに、根まで辿り着けば再帰呼び出しの実行が終わり、今度は Encode 以降の処理が 葉の方向に辿りながら実行されることになります。

プログラム的には行番号4〜7が実行されていきます。
要素番号 k の節が、k の親の左側の子である場合に”0″を、右側の子である場合に”1″を出力すればよいため、[ f ]には「 k の親の左側の子の要素番号が k である」という条件を入れれば話が合います。従って[ f ]の答えはイの「left[parent[k]] = k」となります。
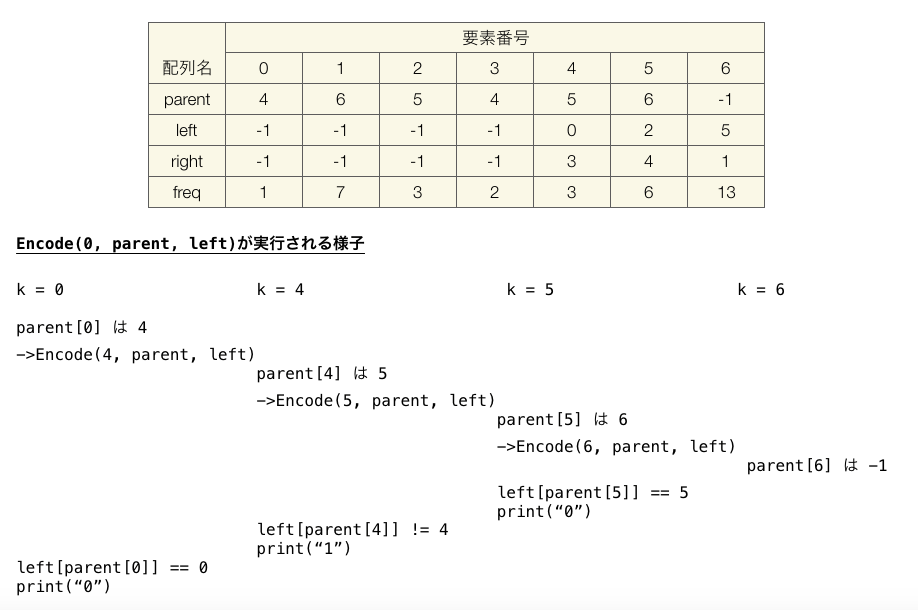
ちなみに設問1の”ABBBBBBBCCCDD”に対して生成されるハフマン木と、それを用いた文字”A”の符号化の様子は下記のようになります。再帰呼び出しがどのように実行されているかが分かりやすいかなと思って書いたのですが、ちょっとは伝わりますかね…。
スポンサーリンク
解いてみた感想
今回の問題は割と解きやすかったのではないかと思います。まずプログラムが副プログラム毎に途切れているので、プログラムの説明とプログラムがどう対応しているのかが分かりやすかったです。さらに設問1はプログラムとは関係ない問題だったので、プログラムが苦手な方でも設問1を解けたという方も多いと思います。
設問1と設問2に関しては問題をしっかり読めれば解ける問題だと思います。ただ設問3は再帰呼び出しの問題なのでちょっと難易度は高めですね…。私は再帰呼び出し苦手です…。
★オススメページ★
下記ページから他の回の解説もたどれます。他の回のアルゴリズム問題の解き方がわからない場合は是非読んでみてください!
 基本情報技術者試験 午後問題「アルゴリズム」過去問の解き方 解説 まとめ
基本情報技術者試験 午後問題「アルゴリズム」過去問の解き方 解説 まとめ
本ページの図・プログラム・問題文について
図やプログラム、問題文はIPA公開の過去問題から引用しています。また図やプログラムに関しては説明に必要な部分に関してのみ加工して使用させていただいております。
出典:平成31年度 春期 基本情報技術者試験(FE)試験区分 午後 問8
アルゴリズム問題の対策(PR)
過去問を解いてみて感触はいかがだったでしょうか?
全く分からなかった...という方もいらっしゃるかもしれません。はっきりいってアルゴリズム問題は、特に慣れないと難易度は高いです。
なので、こういった方にはもっと "簡単なアルゴリズム問題を解いて慣れていく" ことをオススメします。で、この簡単なアルゴリズム問題を解くのにオススメの本が下記の うかる! 基本情報技術者 [午後・アルゴリズム編] です。

オススメする理由は、特に本の前半部分で難易度の低いアルゴリズムの紹介や解説が行われているところです。こういったアルゴリズムの動作などを実際にトレースして追ってみたりすることで簡単な問題からアルゴリズム問題に慣れていくことができます。
また、「アルゴリズムとは?」といったアルゴリズム入門から解説してくれているので、プログラミングをやったことない方にも親切な内容になっています。
アルゴリズム問題に全く手がつかないというような方は、まずは上記のような本でアルゴリズムに慣れるのがオススメです。
慣れてきたら、あとは実際の過去問を解いて "さらに考える力を養う" & "実際のアルゴリズム問題に慣れる" のが良いと思います。
私のサイトでも過去問の解説をしていますので是非参考にしてください。私の解説だけでなく、他の人の解説も参考にしたいような場合には、下記のような過去問の参考書もオススメです(アルゴリズム問題だけでなく、全問題の解説も充実しています)。



解説ありがとうございます。
試験中解答cとfをまちがえてしまったのでなぜ間違ってしまったかが理解することができました。
文さん
コメントありがとうございます。
そう言っていただけると書いた甲斐がありました。
特に f はひっかけっぽい問題だと思います。私も最初見たときは left[k]=k が正解だと思ってしまいました。
実際に数字当てはめて考えてみるとひっかけに気づけることも多いですので、もし時間が余れば(これが難しいのですが…)、頭の中もしくは余白に書いて動作確認してみると良いと思います。
解説ありがとうございます。今回も解説読んで、なんとかわかりました。こんな状態が続いて、本番何もわからないままでした。過去問やアルゴリズムの本で、何回やっても見につかなくて、やり方が問題とは、わかっていながらどうしていいのかと、悩んでいます。基本に戻ってもう一度やり直していますが、実感がわきません。基本情報試験は私には、本当に無理なのかと、次で5回目。読解力上げろって、スランプです。助けてください
まきさん
コメントありがとうございます。
アルゴリズム問題って説明文も分かりにくいし、問題文も長いので、問題見るとテンパってしまうんですよね…。こんなの解けるのか??って。私も最初受験した時はそうでした!多くの方がそう思うでしょうし、特に苦手意識を持っているとこの傾向は強いと思います。
こんなページを書いておいてなんなのですが、
まずはどれだけ時間をかけても良いので、自力で過去問をアルゴリズム問題一回分解いてみるというのはどうでしょうか?ちょっとずつ解いて苦手意識をなくしていきましょう!
もし、問題を解いていて、この回のここの説明文の意味が分からない、考え方が分からない、などあれば、その部分を記載していただければ私がヒントになるような解説をします。回答のレスポンス悪い時もあるかもしれませんが…。
解くときの考え方は、下のページで解説していますので参考にしていただければと思います。
https://daeudaeu.com/tokyo-bocchi/exam/fe/algorithm-easy/#i-7
ありがとうございます。わかりやすくて頼りになります。
早速ですが、設問1は紙に書いてなんとかわかりました。設問2のプログラム説明から、何をすればいいのかわかりません。教えてください。
設問2のcもなんとか理解できました。
素晴らしいです!
d についても同じ感じで解いてみてください!
ちょっと今日は昼間出かけててレスポンス遅いですが、それでもよければ解説しますので、また分からないところがあれば気軽に聞いてください!
ありがとうございます。
だえうさんのわかりやすい解説おかげで最後のfまで、苦しいですがなんとかわかりました。もう一度やり直ししてみて、わからないことは、質問してもよいでしょうか?
いい感じですね!分からないところ、なんだかモヤモヤしているところがあれば是非聞いてください!
焦らなくても良いと思いますが、他の回の過去問も解いてみてくだい。
(ただ平成30秋の問題は難しいのでまだ手を出さないほうがいいかも…)
まだまだ時間は気にする必要はないので、納得するまで考えて解いていくスタンスで良いと思います。
数をこなせばもちろん力も付きますし、自信にも繋がると思いますよー
他の回の問題でもどんどん質問等していただければと思います!
>だえうさんへ
設問2 問d 問題文(4)要約
①親がいない子だけでの節を抽出したい
②節の値は昇順
③節を表す要素組の要素番号は配列node
その個数はnsizeに格納する
行19-24で要素組の要素番号を抽出
行25で節の値は昇順に整列とすると解釈しました。
だえうさんの解説より
行番号21では Sort 関数に渡す配列に要素番号を格納し、
行番号22では要素番号の数をカウントアップして nsize に格納しています。
→解説とプログラムから理解出来ました。
これらの処理に、親が作成されている要素に対して実行してしまうと、
親が作成された要素を含んだ node 配列を Sort に渡してしまいますし、
nsize には親が作成されている要素を含んだ要素数になってしまいますので、 SortNode の説明と話が合いません。
→これでは親を含んだままだと間違って配列をしてしまう。(と解釈しました)
問題文(5)のsort
①sortnodeで作成した、要素組の要素番号の配列を受けとる
②節の値は昇順
③節の値が同じ時の順序は並べ替える直前の順序に従う。
そのため、行番号20の条件には「要素番号 i の節が親を持たないこと」
が入ると考えられます。
→これは親を含んだままだと間違って配列をしてしまうので、
だから要素番号 i の節が親を持たないことが必須条件なのですね。
なので、解答はparent<0
となるわけですね。
こんな風に理解しましたが、正しく理解していますでしょうか?
理解がちょっとあやふやなので、質問しました。
改行がおかしいところがありますが、お許しください
まきさん
その理解であっています!
親を持つ節の要素番号を node 配列に格納することも、
親を持つ節の要素番号の数を nsize に含めることも、
(4)の説明するSortNodeの処理と話が合わないので、
[d]には「親を持たない節であること」が条件になります。
ちょっとくどいかもしれませんが、[d]を解くときの考え方を説明しておきます。
とりあえず穴埋め問題を解くために最初にやるのは、
「穴埋め部分が説明されている箇所がどこであるかをまず見つける」ことだと思います。
で、[d]の場合は(4)の部分になります。
そして、[d]は20行目なので、19-24行目の
「親が作成されていない節を表す要素組の要素番号を抽出」
を行なっている部分の一部になります。
そこでプログラムの 19 – 24 を見てみると、
◾️i: 0, i < size, 1
| ▲ [d]
| |・node[nsize] ← i
| |・nsize ← 1
| ▼
◾️
となっています。ここで、
19 – 24 行目のプログラムにおいて、
「親が作成されていない節を表す要素組の要素番号を抽出」
から何の処理が抜けているのか?を考えてみます。
これはだいたい穴埋め部分を無いものとして考えると見えてくると思います。
今回の場合、[d]の部分がなければ、
node 配列に、i = 0 から i = size – 1 までの
全ての要素番号が格納されてしまいますので、
19 – 24行目で、
「全ての節を表す要素組の要素番号を抽出」
を行うことになってしまいます。
そうなると、説明文にある
「親が作成されていない節を表す要素組の要素番号を抽出」
と話が合わないです。
抜けているのは、「親が作成されていない」の部分です。
なので、[d]には「親が作成されていない」を
判断する条件文が入るだろうと考えることができます。
ここから「親が作成されていない」を
プログラムで表すと具体的にどういう記述になるか、
を考えていけば、答えにたどり着けると思います。
ちなみに、(4)の文章って「かなり」分かりにくいのですが、
分かりやすく書くと下記のようになるのだと思います。
・親が作成されていない節を抽出する
・抽出した節(つまり親が作成されていない節)を値の昇順に整列する
・整列した順に要素組の要素番号を配列 node に格納する
・要素組の個数(つまり親が作成されていない節を表す要素組の個数)を nsize に格納する
なんであんな分かりにくい文章にしているか出題者の意図は分かりませんが…。
ありがとうございます、これですっきりしました。今まで受験して、一から全部理解するのではとずっと思っていましたが、そうではないことが少しだけわかりました。問題文の特徴もこう言った感じで出されるわけですね。
詰まったら要約してみる。与えられた情報をもとに考えてみることの大切さを知りました。
スッキリしていただけたのであれば大変嬉しいです!!
まさにおっしゃられている通りで、全部理解する必要は全くないです。
全部理解して問題解けている人なんて一握りだと思いますよ。
みんな全部理解できないけど、なんとか解いているという感じだと思います。
特に穴埋め問題においては、その穴埋め部分を説明しているのがどの部分かを突き詰めることの方が重要です。
逆にテーマの概要(今回だとハフマン木の概要)やアルゴリズムを理解していても、
穴埋め部分をどの文が説明しているのかが分からなければ問題は解けないです。
そして、アルゴリズム問題に関しては基本的に知識はほとんどいらないです。
なぜなら(これもまきさんがおっしゃられている通り)問題文にその問題を解くための情報があるからです。
是非今回の過去問でつかんだ感触を、他の過去問でも試してみてください(次回の試験までに)!
はじめまして。
設問2を理解できずに困っておりますので、ご教示いただけないでしょうか。
プログラムを1行ずつ理解して進めたく考えています。
図3に即して考えると、最初にプログラム1の6行目のiには1(Bの要素番号)、7行目のjには3(Dの要素番号)が代入されると考えてよろしいでしょうか。
次に8行目のleft[size]ですが、最初のsizeはどの数値を入れればよろしいでしょうか。
9行目のright[size]も同様にわかりません。
i=1, j=3の場合、各要素の個数は2個と3個になるので、sizeには2+3の5が代入されるのでしょうか。
[]の中には要素番号が入るのではないかと思っていたので、[]内がなぜsizeになるのか理解できません。
節について、個数と要素番号があることから混乱している可能性があります。
そもそも入口から私の理解が間違えている可能性が高いと思うので、まずはこの点を教えていただけないでしょうか。
ちなみに、大滝みや子先生の簡単アルゴリズム解法(第4版)には、「本設問では、プログラムの細かい細部まで考える必要はありません。」と書かれていて、設問2のcとdの正答は、プログラムの1行1行の理解を抜きにすれば、こちらのサイトのご説明や前述の書籍の説明で正答の理由は理解できていると思っています。
お手数をおかけしますが、よろしくお願いいたします。
gtk さん
コメントありがとうございます!
>図3に即して考えると、最初にプログラム1の6行目のiには1(Bの要素番号)、7行目のjには3(Dの要素番号)が代入されると考えてよろしいでしょうか。
↑ 合ってます!
が、もしかしたら勘違いされている可能性があるので一応補足しておくと、図3の表はあくまでも図1のハフマン木を配列で表したものになります。
図1は表1の節からハフマン木を作成したものですので、つまり、表1に対して副プログラム Huffman を実行した結果が図3の表になります。
なので、図3は Huffman を実行した後のものなので、プログラムをトレースする際は Huffman 実行前の表1を基にしてトレースした方が良いかもしれません。上手くプログラムをトレースし終われば、その時の結果が図3になると思います。
表1の情報から副プログラム Huffman に入力されるパラメータがどのようなものになるかというと、これは設問2の (3) あたりを読むと分かります。
まず、設問2の (3) の①より、size は葉である節の個数となります。問8の冒頭の (2) に記載されている通り、葉とは “子を持たない節” です。最初はどの節も子を持たないので、全ての節が葉となります。表1には4つ分の節の情報が記載されているので、size は 4 になります。
また、設問2の (3) の②③④より、まず配列 parent、left、right は初期化された配列であることが分かります。で、”初期化された配列” が何かというと、これは設問2の (1) に書いてある通り、全ての要素を -1 とした配列になります。
さらに、配列 freq は 設問2の (3) の⑤より、各要素に出現回数が格納されていることになります。
なので、各配列の要素の情報を表すと下記のようになります(各要素をカンマで区切っています)
parent = {-1, -1, -1, -1, -1, ..., -1} left = {-1, -1, -1, -1, -1, ..., -1} right = {-1, -1, -1, -1, -1, ..., -1} freq = {10, 2, 4, 3, -1, ..., -1}↑ もしプログラムをトレースする場合は、これらを Huffman のパラメータとしてトレースした方が良いと思います(表になっていないので分かりにくいかもしれませんが…)。
>次に8行目のleft[size]ですが、最初のsizeはどの数値を入れればよろしいでしょうか。
9行目のright[size]も同様にわかりません。
↑ ここまで述べてきた通り、表1に基づいたパラメータで考えると、size は 4 になります。図3で考えると、葉でない節もあるのでちょっと分かりにくいかもしれません…。
>[]の中には要素番号が入るのではないかと思っていたので、[]内がなぜsizeになるのか理解できません。
↑ この認識は合っています。つまり、[ ] には要素番号が入ります。なので、size は要素番号として扱われていることになります。
アルゴリズム問題は先入観は捨てて解いた方が良いです。「size = サイズ」というイメージがあると思いますが、[size] というふうに記述されている場合は、size は要素番号として扱われていることになります。
ですので、1回目の 8 行目から 10 行目の処理では left[4]、right[4]、freq[4] にそれぞれ値が格納されることになります(size = 4 なので)。現状、節の要素は 0 〜 3 のみですので、要素 4 に値を格納することで、新たな節が作成されるイメージです。
具体的に1回目の 8 〜 12 行目を実行した後の各配列の要素の状態は下記のようになると思います。
parent = {-1, 4, -1, 4, -1, ..., -1} left = {-1, -1, -1, -1, 1, ..., -1} right = {-1, -1, -1, -1, 3, ..., -1} freq = {10, 2, 4, 3, 5, ..., -1}各配列の要素番号 4 の部分に値が格納されたことで節 4 が追加されました。
また、left[4] = 1・right[4] = 3 さらには、paraent[1] = 4・parent[3] = 4 となったことで、節 4 と節 3・節 1に親子関係が生まれるようになりました。
こんな感じで、配列の値を更新していくことで節の追加と親子関係の構築を行なっていくのが幅プログラム Huffman の動作になります。
最初にも言ったように、図3からではなく、表1から Huffman の動きを追うことを試した方が良いと思います。まずはここまでの情報の整理と、表1に基づいて Huffman を実行した場合に、2週目以降のプログラムの動作のトレースをしてみてはいかがでしょう?
daeu様
早速に詳しいご説明をいただき、本当にありがとうございます!
とてもよくわかり、すっきりしました。
トレースできて、嬉しいです。
「アルゴリズム問題は先入観は捨てて解いた方が良い」ということは肝に銘じておきたいです。
これからも、こちらのサイトで勉強させていただければと思います。
よろしくお願いします。
gtk さん
ご返信ありがとうございます!
スッキリしたのであれば私としても嬉しいです。
>「アルゴリズム問題は先入観は捨てて解いた方が良い」
↑ 最近コレ重要だと思い始めたんですよね…。
アルゴリズム問題に解くための情報は全てその問題文とプログラムの中にあり、逆にここに書かれていない情報はアルゴリズム問題を解くためには不要な情報になります。
なので、むしろその不要な情報があると変に問題文やプログラムを曲解してしまって間違うことがあると思うんですよねー。まぁでも知識があると解くの楽になる問題もあるので一概には言えないかもしれませんが、事前知識は捨てて解いた方が無難だとは思います。
>これからも、こちらのサイトで勉強させていただければと思います。
ありがとうございます!
また不明点などありましたら気軽にコメントいただければ幸いです(レスポンス悪かったらすみません…)。