
このページでは N + 1 問題について解説していきます。
いきなりですが、みなさん、Django でのウェブアプリ開発を楽しんでいらっしゃいますか?
Django を利用すればウェブアプリの開発を簡単に行うことができますが、それでもウェブアプリ開発に難しさを感じておられる方もいらっしゃるかもしれません。でも、このページを訪れてくださったという方は、きっとウェブアプリの開発を楽しいと感じられていたり、これからウェブアプリの開発を楽しみたいという方が多いのではないかと思います。実際、ウェブアプリに機能を追加したり、ウェブアプリの見た目を自分好みのものに仕立てていく作業は楽しいと思います。
が、今回は少し現実的な話をしていきます。今回は、ページのタイトルにもなっている N + 1 問題を扱っていきます。この N + 1 問題は機能追加や見た目を綺麗にするようなものではなく、ウェブアプリのパフォーマンス(反応速度や処理速度など)に関わるものになります。なので、このページを読むことで、あなたがウェブアプリで実現可能な機能が増えるというわけではありません。
ですが、今回説明する N + 1 問題は、ウェブアプリを公開していく上では必ず解決しておかなければならない問題となります。そして、この N + 1 問題は Django 利用者が陥りやすい問題です。
もしかしたら、つまらない題材だと感じる方もおられるかもしれませんが、できるだけ分かりやすく解説していきますので、是非 N + 1 問題について、そしてこの問題の解決方法について学んでいっていただければと思います。
Contents
N + 1 問題
では、早速 N + 1 問題について解説していきたいと思います。
N + 1 問題:件数に比例してクエリ発行回数が増加すること
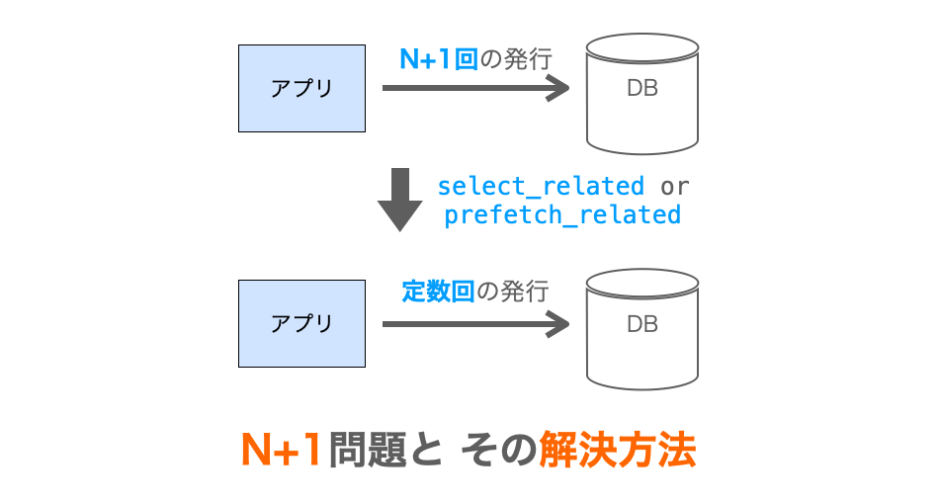
N + 1 問題とは、簡単に言ってしまえばページに表示するレコードの件数に比例してデータベースへのクエリ発行回数が増加してしまう問題のことを言います。レコードの件数を N として考えれば、Nに比例してクエリ発行回数が増加する問題のことを N + 1 問題と言います。
それなら、N 問題と呼べばよさそうなものですが、もちろん、この + 1 にも意味があります。これに関しては後述で解説します。
クエリとは、データベースへの問い合わせや要求を表す言葉で、N + 1 問題の場合のクエリはレコードの取得の要求と考えて良いでしょう。N + 1 問題が発生すると表示するレコードの件数に比例してデータベースへの問い合わせが多くなるため、基本的にはデータベースで管理するレコードに比例してウェブアプリのパフォーマンスが低下することになります。例えばウェブアプリの登録者やウェブアプリに登録されているコメントなどが増えれば増えるほど、つまりウェブアプリが人気が出れば出るほどウェブアプリのパフォーマンスが低下することになります。
公開当初はウェブアプリに登録されているコメントが少なくて快適に利用できていたウェブアプリも、人気が出て登録されているコメントが多くなるとウェブアプリの処理時間が増加し、いわゆる重いウェブアプリとなってしまいます。重いとストレスが溜まるので、ウェブアプリの利用者が減ってしまうかもしれないですね…。
そういったことにならないためにも、N + 1 問題は解決しておく必要があります。
スポンサーリンク
N + 1 問題の解決:件数に比例したクエリの発行回数の増加を解消すること
前述の通り、N + 1 問題とは表示するレコードの件数に比例してクエリの発行回数が多くなることです。そのため、N + 1 問題の解決とは、この “表示するレコードの件数に比例してクエリ発行回数が増えること” を解消することになります。
なので、このページでは、まず N + 1 問題が発生する原因について説明した後、”表示するレコードの件数に比例してクエリ発行回数が増えること” を解消する方法について解説を行なっていきます。
実は、N + 1 問題と聞くと難しそうに感じますが、発生する原因も、それを解決する方法も単純ですので安心してください。
Django では N + 1 問題が発生しても気づきにくい
特に Django を利用している場合、この N + 1 問題が発生していても気付きにくいという点に注意が必要です。Django を利用していれば、クエリを発行する処理を記述しなくても、モデルクラスやモデルクラスのインスタンスを扱うことでデータベースの操作が行えます。なので、クエリを意識しなくてもデータベースにレコードを登録したり、データベースからレコードを取得したりできます。ですが、実際にはウェブアプリからデータベースにクエリが発行されており、気付かぬうちに N + 1 問題も発生していることが多いです。
ということで、これは Django だけには限らないのですが、クエリを発行する処理を記述しなくてもデータベースの操作が実現可能なフレームワークやライブラリを利用している場合、N + 1 問題の発生に気づきにくく、特に N + 1 問題に注意が必要となります。
N + 1 問題の発生原因
前述の通り、N + 1 問題とはクエリの発行回数が件数に比例して増加してしまうことになります。
つぎは、この N + 1 問題が発生する原因について、必要な内容を復習しながら解説をしていきたいと思います。
スポンサーリンク
モデルとテーブルの関係
前述の通り、この N + 1 問題はデータベースに関する問題となります。
このデータベースに密接に関わるのが Django のモデルとなります。
Django では models.py にモデルクラスを定義し、そのモデルクラスや、そのインスタンスを利用してデータベースのテーブルの操作を行うことになります。下記ページでも解説しているとおり、このモデルクラスがテーブルであり、そのインスタンスが、そのテーブルのレコードに対応します。
 【Django入門6】モデルの基本
【Django入門6】モデルの基本
例えば、下記のように models.py に Comment というモデルクラスを定義したとします。
from django.db import models
class Comment(models.Model):
text = models.CharField(max_length=256)このように models.py を変更したのちにマイグレーションを実行すれば、Comment に対応するテーブルがデータベースに作成されることになります(id 等のプライマリーキーに関しては、フィールドとして定義しなくても自動的にテーブルに追加されます)。
そして、この Comment のインスタンスを生成し、そのインスタンスに save メソッドを実行させることで、Comment のテーブルに新たなレコードを登録することができます。
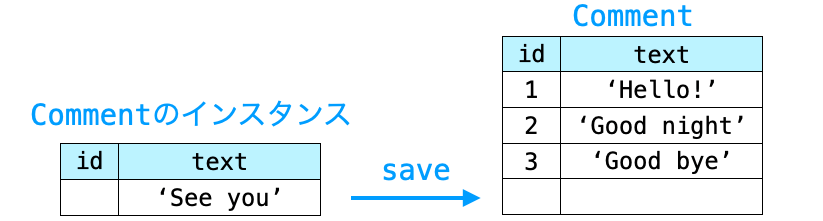
このように、モデルクラスはテーブルに対応し、そのインスタンスはレコードに対応しています。
ちなみに、マイグレーションによって作成されるテーブル名の形式は アプリ名_モデルクラス名 (全て小文字) となります。例えば、アプリ名が app の場合、Comment のテーブルの名前は app_comment となります。以降でクエリの例などを示していきますが、全てアプリ名が app の時の例となります。
クエリの発行
N + 1 問題を理解する上で重要なのは、こういったデータベースに保存されているレコードの情報はデータベースから取得しないと利用できないという点になります。例えば、レコードの各フィールドの値を表示しようと思うと、そのレコードをデータベースから事前に取得しておく必要があります。
ウェブアプリとデータベースは別物であり、あらかじめウェブアプリがデータベースに保存されているレコードを所持しているというわけではありません。従って、ウェブアプリでレコードの情報を表示したいのであれば、そのレコードをデータベースから取得する必要があります。そして、その取得などの、データベースへの要求がクエリとなります。
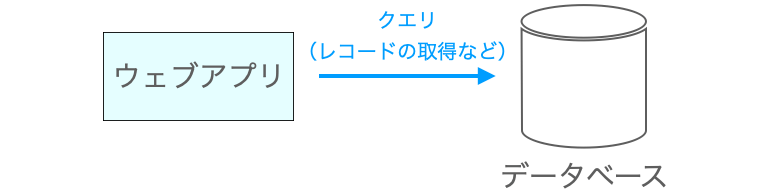
レコードの取得が必要になったタイミングで発行される
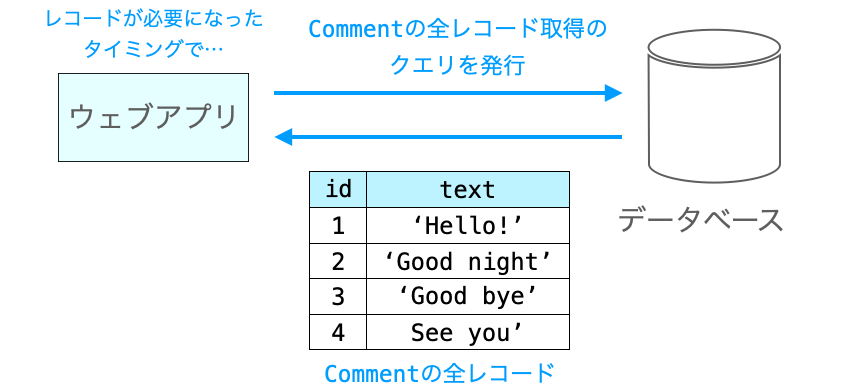
ここで、このクエリが発行されるタイミングや発行されるクエリの内容について確認するため、ビューで下記のような処理を行うことについて考えたいと思います。Comment は先程紹介したものと同じモデルクラスとします。
この処理が実行されれば、Comment のテーブルの全レコードの text フィールドを print 関数で出力することができます。レコードの情報が表示されるということは、データベースからレコードの取得が行われているということになります。つまり、この処理のどこかでレコードを取得するためのクエリが発行されることになります。
comments = Comment.objects.all()
for comment in comments:
print(comment.text)上記の処理を直感的に捉えれば、1行目で Comment テーブルの全レコードを取得し、次の for ループで取得した全レコードの text をフィールドを表示していると考えることができます。
なので、1行目を実行した際にクエリが発行されるようにも思えますが、実はクエリが発行されるのは2行目の for comment in comments: が実行されるタイミングとなります。そして、この時に発行されるクエリは下記のようなものになります。これは、テーブル Comment の全てのフィールドを含む全レコードを取得するためのクエリとなります。
SELECT "app_comment"."id",
"app_comment"."text",
FROM "app_comment"
ポイントは、Django ではクエリはレコードが必要になったタイミングで自動的に発行されるようになっているという点になります。もっと正確に言えばクエリセットが評価されるタイミングで自動的に発行されるのですが、まずはレコードが必要になったタイミングでクエリが発行されるとイメージしていただければ良いと思います。
そのため、上記では comments = Comment.objects.all() がコードとしてはレコードを取得する処理のようにも思えますが、この時点ではまだレコードが必要でないため、プログラムの動作としては、comments = Comment.objects.all() が実行されてもクエリは発行されません。例えば、下記のような処理のみを行ってもクエリは発行されません。
comments = Comment.objects.all()ですが、for comment in comments: では全レコードに対するループを実現するため、ループ回数等を決定するためにレコードが必要となります。ですが、この時点でウェブアプリはレコードを所持していません。そのため、この時点で全レコードを取得するためのクエリが発行されることになります。そして、このクエリの発行によってウェブアプリは Comment のテーブルの全レコードを所持することになります。
レコードの取得が不要であればクエリは発行されない
さらに、ループ内の処理では各レコードの text フィールドを出力することになります。当然、この処理でも Comment のレコードが必要になるのですが、既にウェブアプリは for comment in comments: でのクエリの発行によって Comment の全レコードが取得されているため、その取得済みのレコードを参照して各レコードの text フィールドを出力することが可能となります。したがって、このループ内の処理ではクエリの発行は行われません。
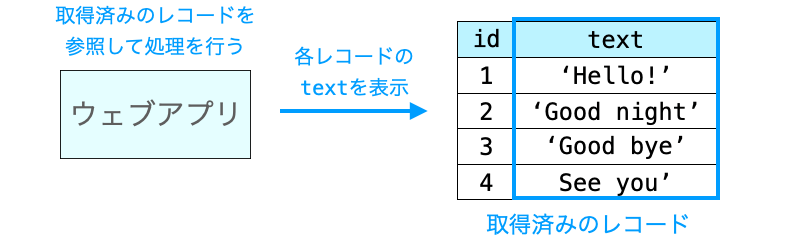
このように、レコードが必要になった際には Django フレームワークが裏側で自動的にクエリを発行するようになっています。逆に、レコードが不要なのであればクエリの発行は行われません。
クエリは自動的に発行される
ここで特に重要なのは、Django ではクエリの発行はレコードが必要になった際に自動的に Django フレームワークから発行されるという点になります。そのため、Django を利用すれば、クエリの発行に関しては意識しなくてもウェブアプリを開発することが可能となります。
ですが、Django ではクエリの発行を意識しなくても良いため、開発者が意図していないタイミングでクエリが発行されたとしても、それに気づきにくいです。先程の例のような処理を記述したことがあっても、for comment in comments: の行でクエリが発行されることを知らなかった人も多いのではないかと思います。そして、クエリの発行を意識しなくても良いため、今回扱っている N + 1 問題が発生したとしても、それに気付けない開発者が多くなります。
クエリの発行タイミングに関しては少し難しい話に感じるかもしれませんが、N + 1 問題を理解する上で重要なのは、結局ウェブアプリは所持していないレコードの情報を扱うためにはデータベースからのレコードの取得が必要となり、その際にクエリが発行されるという点になります。
逆に、必要なレコードをウェブアプリが既に所持しているのであればクエリは発行されません。
その例が、上記の例であり、for comment in comments: で必要なレコードを取得しておき、さらに for ループ内部で取得済みのレコードの情報を表示するだけであれば、for ループ内部でレコードを取得するためのクエリは発行されることはありません。ですが、for ループ内部で “取得済みのレコード以外” のレコードの情報を表示しようとすると for ループ内部でクエリが発行されることになってしまいます。そして、この for ループ内部でのクエリの発行が行われる際に N + 1 問題が発生することになります。
実は、正確には、レコードを既に取得している場合でもクエリが発行される場合があります
その点については後述で補足しますので、まずは、レコードを既に取得していれば、そのレコードを取得するためのクエリは発行されないという “当たり前” の前提を頭に入れて記事を読み進めていただければと思います
じゃあ、どんな時に for ループ内部で “取得済みのレコード以外” のレコードの情報を表示することになるのか、次はその点について考えていきたいと思います。ズバリ言うと、これはリレーションを利用している場合になります。
と言うことで、次の節ではリレーションのおさらいをしていきたいと思います。が、ここで少し、ここまでの説明に補足を加えておきたいと思います。
発行するクエリの情報の更新
ここまでの説明で、下記ではクエリは発行されないと説明しました。では、下記では何が行われるのでしょうか?
comments = Comment.objects.all()上記で行われるのは、直感的にはインスタンス(レコード)の取得と考えて良いと思います。コード的にはそのように考えて問題ありません。
ですが、実際の動作としては、上記で行われるのはクエリの生成のみとなります。もっと正確に言えば、クエリを生成するための情報の設定のみが行われることになるのですが、簡単に “クエリの生成” と考えて説明していきたいと思います。
具体的には、上記では Comment の全レコードを取得するためのクエリの生成が行われることになります。ですが、前述の通り、この時点ではクエリは発行されません。クエリが発行されるのはレコードが必要になったタイミングであり、さらにクエリは、必要なレコードのみを取得するように上記で生成されたクエリを後から更新して発行される可能性があります。
例えば、下記の場合であれば、Comment.objects.all() で生成されたクエリが for comment in comments: で発行されることになります。Comment.objects.all() では Comment のテーブルの全レコードを取得するためのクエリが生成されます。
comments = Comment.objects.all()
for comment in comments:
print(comment.text)ですが、下記の場合、for ループを実現するのに必要となる Comment のレコードは Comment のテーブルの全てではなく、先頭の 5 件分のみで良いことになります。
comments = Comment.objects.all()
for comment in comments[:5]:
print(comment.text)したがって、この場合は Comment.objects.all() で全レコードを取得するために生成されたクエリを for comment in comments[:5]: で先頭の 5 件のレコードのみを取得するクエリに上書きし、その上書き後のクエリが発行されることになります。必要なレコードが 5 件だけなのに全てのレコードを取得するのは無駄なので、実際に必要なレコードのみが取得されるよう Django フレームワークが自動的にクエリを更新してくれるというわけです。
このように、クエリは必要なレコードのみの取得に絞られるようにどんどん更新され、最終的に必要なレコードのみが取得されるようにクエリが発行されることになります。
発行されるクエリの確認方法
また、クエリは Django フレームワークから自動的に発行されるため、どのタイミングでどんなクエリが発行されるかが通常の Django 使い方だと分かりにくいです。
もし、クエリが発行されるタイミングや発行されるクエリの内容を確認したい場合、下記ページで紹介している django-debug-toolbar を利用することをオススメします。
 【Django】発行されるクエリの確認方法(django-debug-toolbar)
【Django】発行されるクエリの確認方法(django-debug-toolbar)
django-debug-toolbar を利用すれば、ページ表示後に、そのページを表示するために発行されたクエリの内容や、どの処理を実行した時にクエリが発行されたかを確認することができるようになります。このページの本題である N + 1 問題が発生しているかどうかも確認しやすくなるため、ウェブアプリを公開する前に一度は django-debug-toolbar を利用して自身のウェブアプリのクエリの情報を確認しておくことをオススメします。
リレーション
さて、少し話が逸れましたが、次はリレーションについておさらいしていきます。このリレーションを利用している場合、N + 1 問題が発生する可能性があります。
リレーションについての詳細は下記ページで解説していますので、詳しく知りたい方は別途下記ページを参照していただければと思います。
 【Django入門7】リレーションの基本
【Django入門7】リレーションの基本
ここでは、リレーションについて、N + 1 問題に関連する部分のみを簡単に解説していきます。
リレーションとは
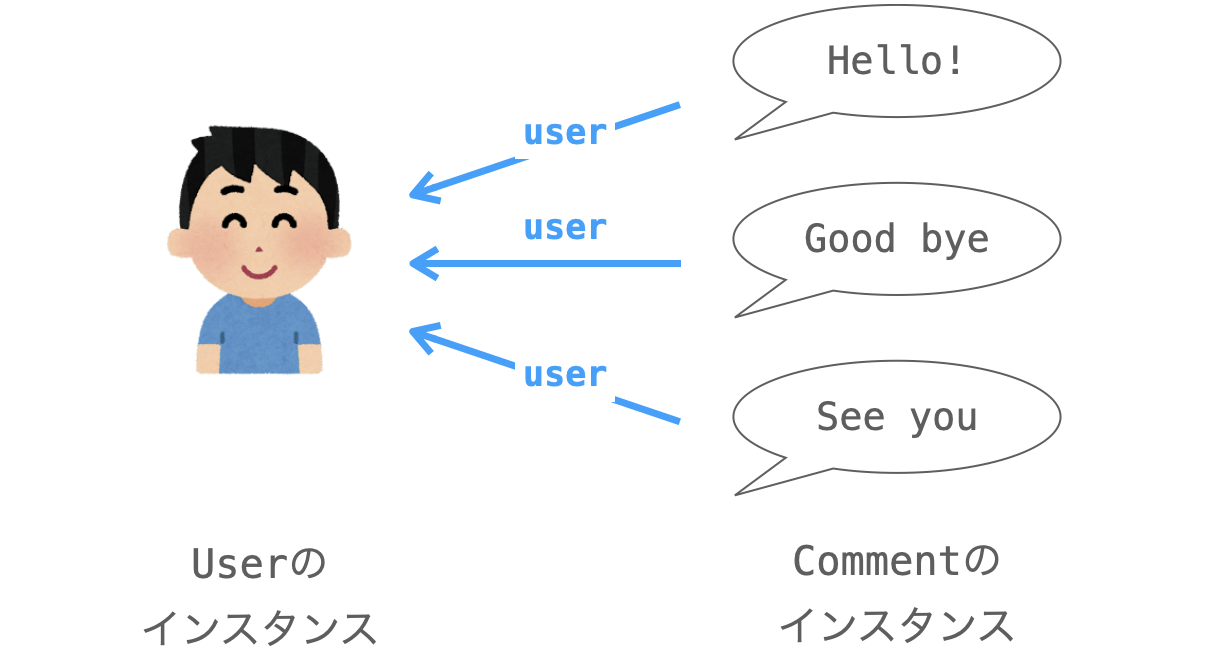
リレーションとはインスタンス同士を関連付けることであり、Django では、モデルクラスにリレーションフィールドを定義することでリレーションを利用することが可能となります。リレーションフィールドには下記の3種類が存在し、定義するフィールドによって実現可能なリレーションが異なります。
OneToOneField:1対1のリレーションForeignKey:多対1のリレーションManyToManyField:多対多のリレーション
例えば、models.py に下記のように User と Comment を定義したとしましょう。この場合、User と Comment は互いに独立したモデルクラスとなり、お互いのインスタンスを関連付けることはできません。
from django.db import models
class User(models.Model):
name = models.CharField(max_length=256)
class Comment(models.Model):
text = models.CharField(max_length=256)それに対し、下記のように Comment に user = models.ForeignKey(User,略) を定義した場合、ForeignKey はリレーションフィールドであるため、User と Comment とが関連性を持つことになります。そして、これによって User のインスタンスと Comment のインスタンスとが関連付けることができるようになります。以降では、このリレーションフィールドの第1引数に指定するモデルクラスのことを 関連モデルクラス と呼ばせていただきます。
from django.db import models
class User(models.Model):
name = models.CharField(max_length=256)
class Comment(models.Model):
text = models.CharField(max_length=256)
user = models.ForeignKey(User, on_delete=models.CASCADE)ForeignKey は多対1の関連付けを行うためのリレーションフィールドであり、その ForeignKey のフィールドを定義したモデルクラス(上記の場合は Comment)のインスタンスは、関連モデルクラス (上記の場合は User)の1つのインスタンスと関連付けが可能となります。それに対し、関連モデルクラス のインスタンスは、ForeignKey のフィールドを定義したモデルクラスの複数のインスタンスと関連付けが可能となります。
この「関連付け」の意味合いはウェブアプリによって異なりますが、上記の場合は、Comment のインスタンスは掲示板アプリに投稿されたコメントを表し、その user フィールドは、そのコメントを投稿したユーザーを管理するフィールドであると考えると関係性がイメージしやすくなると思います。
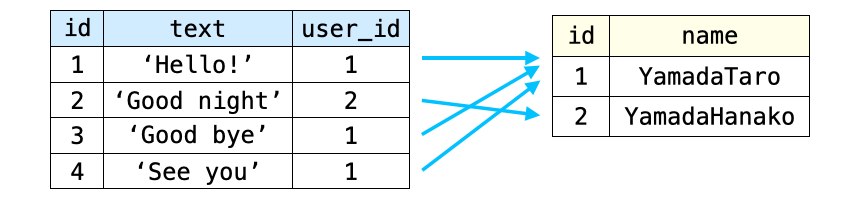
また、テーブル観点で考えると、ForeignKey を定義した場合は、その ForeignKey を定義した側のモデルクラスのテーブルに、関連モデルクラス のレコードとの関連性を管理するためのフィールド(カラム)が追加されることになります。そして、このフィールドには、関連付け相手となるレコードのプライマリーキーが格納され、それによって各インスタンスの関連付けが管理されることになります。
例えば前述のように User と Comment を定義した場合は、Comment のテーブルに user_id というフィールドが追加され、このフィールドには User のレコードのプライマリーキー(id)が格納されることになります。そのため、このフィールドから、関連付け相手の User のレコードを特定することができるようになります。
そして、このように関連付けられたインスタンスは互いにデータ属性から他方のインスタンスにアクセスすることができるようになります。例えば下記のような処理を行えば、Comment のインスタンスから投稿者の名前を表示するようなことが可能です。
# commentはCommentのインスタンス
print(comment.user.name)ここで重要な点は2つあって、1つ目はリレーションを利用することで、特定のインスタンスから、そのインスタンスに関連付けられた “他のモデルクラスのインスタンス” にアクセスできるようになるという点になります。リレーションを利用していなければ、特定のモデルクラスのインスタンスからは自身のフィールドにしかアクセスすることができません。ですが、リレーションを利用することで、自身のインスタンスのフィールドだけでなく、他のモデルクラスのインスタンスにアクセスできるようになります。
2つ目は、リレーションの利用によって複数のモデルクラスに関連性を持たせることができるものの、結局これらのテーブルは別のものという点になります。
関連付け可能なインスタンスの個数
さて、先ほど説明したように、リレーションとはインスタンス同士を関連付けることであり、モデルクラスにリレーションフィールドを定義することで、そのフィールドの定義先のモデルクラスのインスタンスと、関連モデルクラス のインスタンスとを関連付けることが可能となります。
ただし、各モデルクラスのインスタンスに関連付け可能なインスタンスの個数は、定義するリレーションフィールドの種類、および、そのインスタンスが “フィールドの定義先のモデルクラスのインスタンス” or “関連モデルクラス のインスタンス” のどちらであるかによって変化することになります。
例えば、先ほども例に示した下記の User と Comment の場合、リレーションフィールドの定義先のモデルクラスは Comment であり、その 関連モデルクラス は User となります。また、リレーションフィールドの種類は ForeignKey になります。この ForeignKey は、多対1のリレーションを実現するために定義するフィールドになります。
from django.db import models
class User(models.Model):
name = models.CharField(max_length=256)
class Comment(models.Model):
text = models.CharField(max_length=256)
user = models.ForeignKey(User, on_delete=models.CASCADE)で、この場合、Comment のインスタンスに関連付け可能な User のインスタンスの個数は 1 となります。それに対し、User のインスタンスに関連付け可能な Comment のインスタンスの個数は 多 となります。
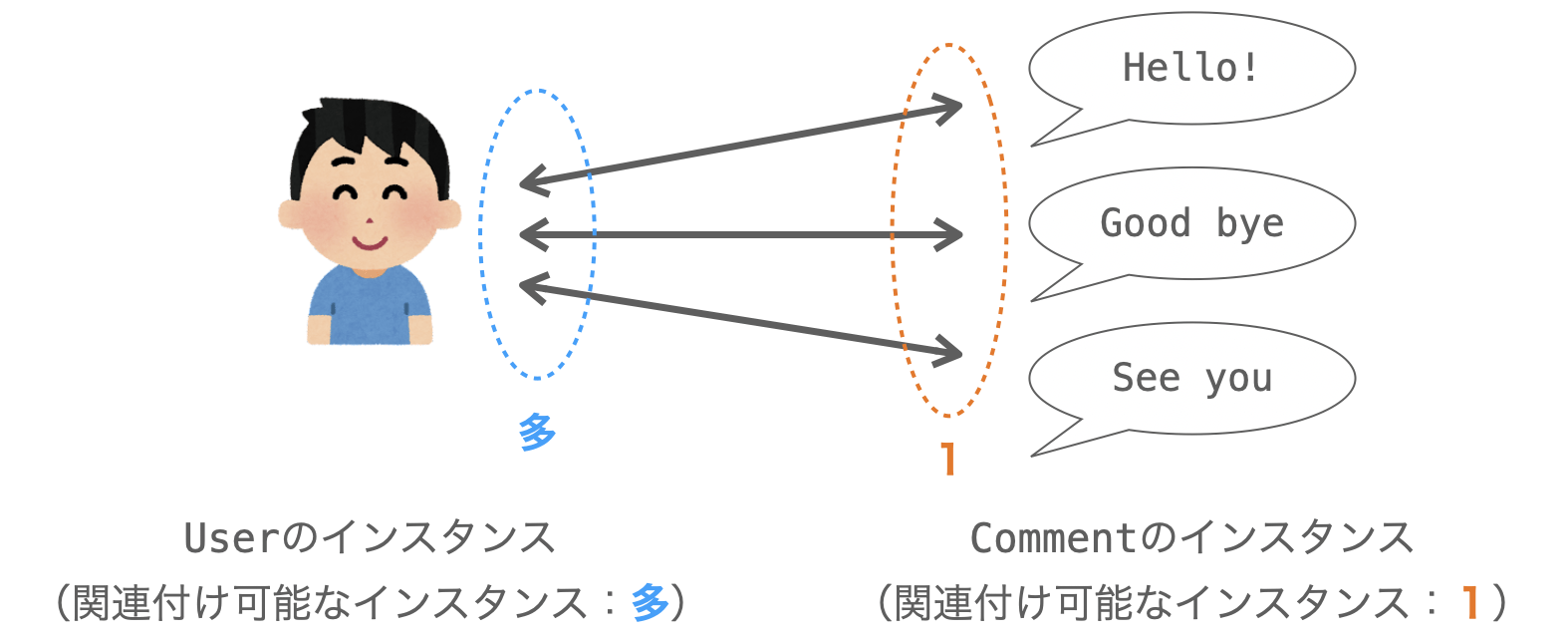
このように、インスタンスが “フィールドの定義先のモデルクラスのインスタンス” or “関連モデルクラス のインスタンス” のどちらであるかによって、そのインスタンスに関連付け可能な個数が変わります(1 or 多)。さらに、定義するリレーションフィールドの種類によっても関連付け可能な個数が変化します。
この、関連付け可能なインスタンスの個数は、リレーションを利用するときだけでなく、N + 1 問題を解決する上でも重要な指標となるため、これに関しては理解しておいた方が良いと思います。
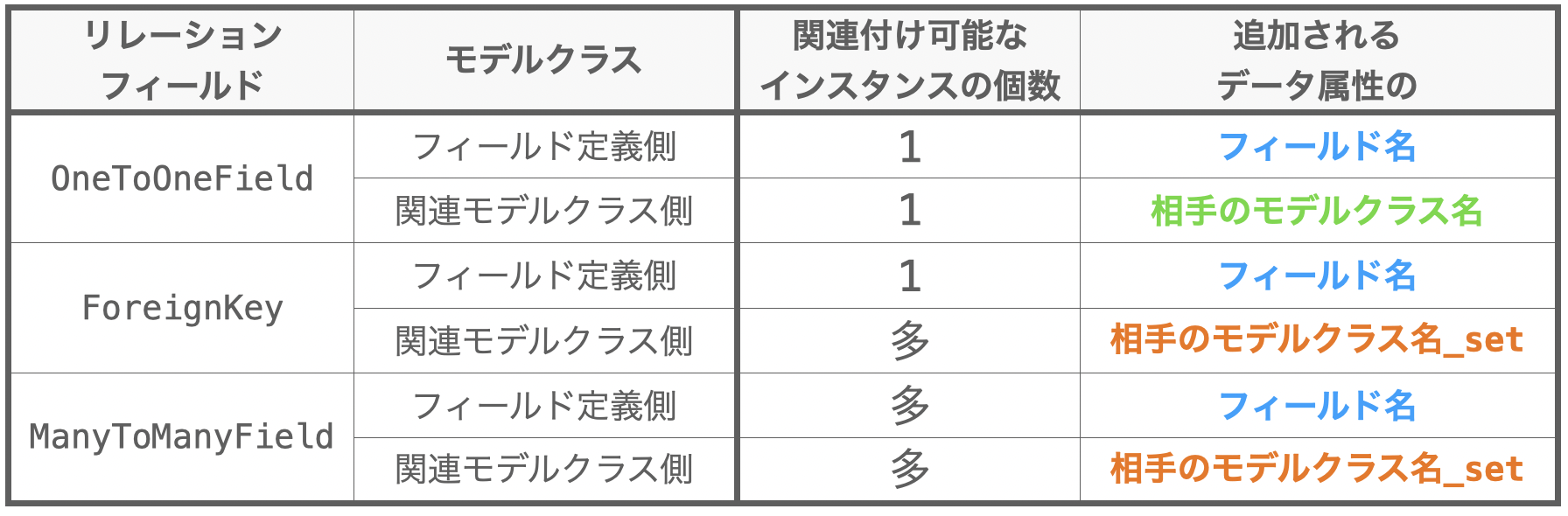
結論を言うと、関連付け可能なインスタンスの個数は下図の表のようになります。

リレーションフィールドの定義によって追加されるデータ属性の名称
また、リレーションフィールドを定義することで、その定義先のモデルクラスと、関連モデルクラス に指定されたモデルクラスにデータ属性が追加されることになります。インスタンスの関連付けは、このデータ属性を利用して実施することになります。
【Django入門7】リレーションの基本
また、この追加されるデータ属性の名称は、N + 1 問題を解決する時に実行するメソッドの引数に指定することになるため、このデータ属性の名称についてもしっかり理解しておいた方が良いです。
この追加されるデータ属性の名称は、定義するリレーションフィールドの種類、および、そのリレーションフィールドの定義先のモデルクラス or 関連モデルクラス のどちらであるかによって変わります。これをまとめたのが下図の表になります。
例えば、先ほども例に示した下記の User と Comment の場合、リレーションフィールドの定義先のモデルクラスは Comment であり、その 関連モデルクラス は User となります。また、リレーションフィールドの種類は ForeignKey になります。
from django.db import models
class User(models.Model):
name = models.CharField(max_length=256)
class Comment(models.Model):
text = models.CharField(max_length=256)
user = models.ForeignKey(User, on_delete=models.CASCADE)そのため、上記のように ForeignKey を定義することで、Comment のインスタンスにはデータ属性 user が追加されることになり、User のインスタンスにはデータ属性 comment_set が追加されることになります。
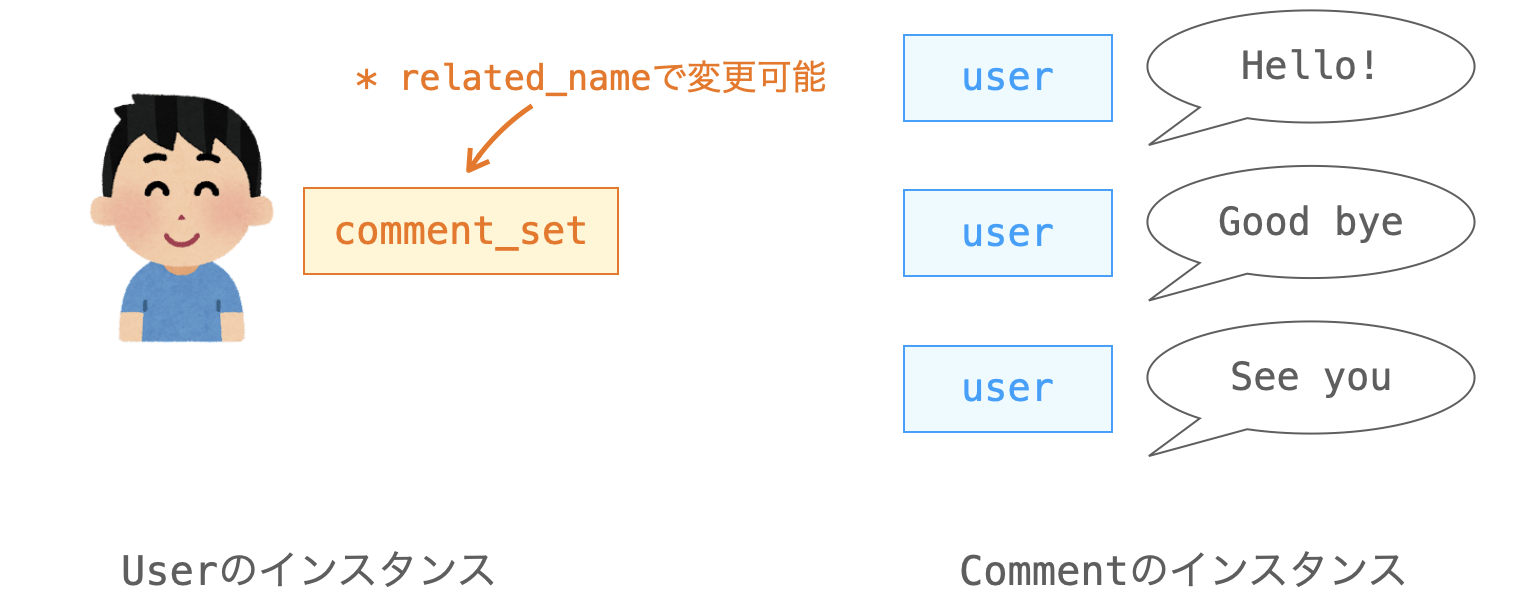
また、関連モデルクラス 側に追加されるデータ属性の名称は、リレーションフィールドに related_name 引数を指定することで開発者が任意の名前に変更することが可能です。
とりあえず簡単に説明しましたが、リレーションに関しては以上のことを理解しておけば、N + 1 問題、及び、N + 1 問題の解決手順も理解しやすくなると思います。
スポンサーリンク
N + 1 問題
実は、先ほど説明したリレーションを利用した場合に N + 1 問題が発生することがあります。
ここで、下記のように User と Comment を定義した場合のクエリの発行回数について考えていきたいと思います。
from django.db import models
class User(models.Model):
name = models.CharField(max_length=256)
class Comment(models.Model):
text = models.CharField(max_length=256)
user = models.ForeignKey(User, on_delete=models.CASCADE)まずは、下記の処理について考えてみましょう。この処理では、クエリは何回発行されることになるでしょうか?
comments = Comment.objects.all()
for comment in comments:
print(comment.text)答えは 1 回ですね!
これは クエリの発行 でも確認した例で、2行目の for comment in comments: が実行されるタイミングで Comment のテーブルのレコードを全て取得するためのクエリが 1 回発行されます。そして、for ループ内の処理は既に取得済みの Comment のレコードのみで実現することができるため、for ループ内の処理ではクエリは発行されません。そのため、クエリの発行回数は合計 1 回のみとなります。
それに対し、下記の例ではクエリは何回発行されるでしょうか?
comments = Comment.objects.all()
for comment in comments:
print(comment.user.name)この場合も、先ほどと同様に comment のデータ属性を print 関数で出力しているだけです。先ほどと同様の感覚でこの処理も記述することが可能ですが、先程の例とは決定的な違いがあります。もうここまで解説を読んでくださった方であればお気づきだと思いますが、それは、comment.user.name の出力を行うためには2つのレコードが必要になるという点になります。
まず、comment は Comment のテーブルのレコードとなるため、Comment のテーブルのレコードが必要となります。さらに、comment.user は comment と関連付けられた User のテーブルのレコードとなりますので、User のテーブルのレコードも必要になります。comment.user.name は User のテーブルのレコードの name フィールドですので、User のテーブルのレコードを取得すれば、この name フィールドは出力可能となります。
クエリの発行 (1 回)
そして、上記の処理では、これまで通り for comment in comments: の実行時にクエリが発行され、Comment のテーブルの全レコードが取得されることになります。つまり、ここでクエリが 1 回発行されることになります。
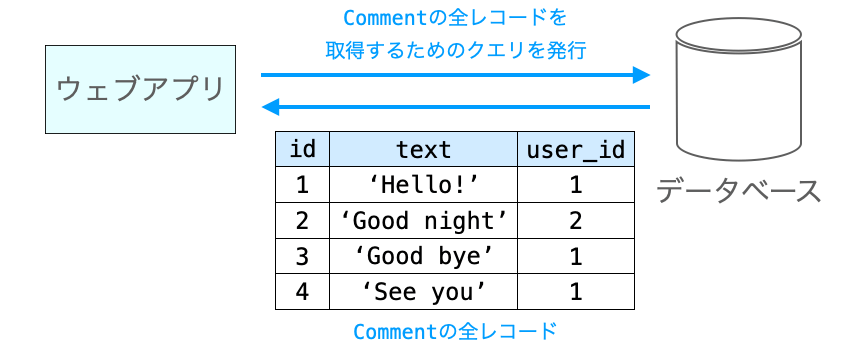
ここで Comment のテーブルの全レコードが取得されるため、for ループ内部の処理では Comment のレコードを取得するためのクエリの発行は不要となります。
クエリの発行 (N 回)
ですが、ここで取得されるのはあくまでも Comment のテーブルのレコードのみであり、User のテーブルのレコードは取得されません。
そのため、for ループ内部の処理に移る前に取得されたレコードのみでは print(comment.user.name) を実行することはできません。別途 User のテーブルのレコードが必要となります。なので、print(comment.user.name) が実行されるタイミングで User のテーブルのレコードを取得するためのクエリが発行されることになります。
ここで必要になるレコードは comment.user で関連付けられる User のテーブルのレコードととなります。もっと具体的にいうと、その Comment のレコードの “user_id フィールドと id フィールドが一致する User のテーブルのレコード” となります。例えば、その Comment のレコードの user_id フィールドが 7 であれば、id が 7 である User のレコードが必要となります。
そのため、この user_id に応じたレコードの取得を行うためのクエリが発行されることになります。そして、クエリを発行してレコードを取得した後に print(comment.user.name) よって出力が行われることになります。
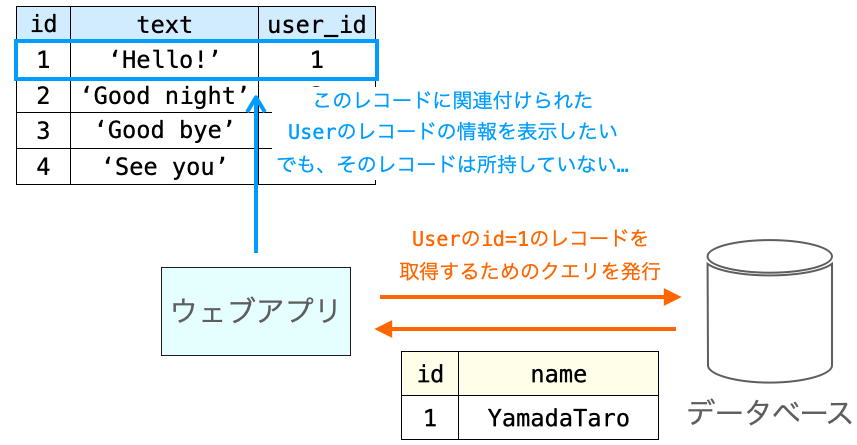
ここで発行されるクエリは下記のようなものになります。下記における WHERE "app_user"."id" = '45' が、”user_id と一致する id を持つレコード” を要求するために指定する条件となります。45 の部分は user_id によって変化します。
SELECT "app_user"."id",
"app_user"."name"
FROM "app_user"
WHERE "app_user"."id" = '45'
LIMIT 21
そして、次の周のループに移った際には、comment は先ほどとは異なる Comment のテーブルのレコードとなるため、comment.user (user_id) によって関連付けられる User のレコードも異なる可能性があります。そのため、再度 comment.user に応じたレコードの取得を行うためのクエリが発行されることになります。次以降も同様ですね!
つまり、ループ内部の処理が実行されるたびに User のテーブルのレコードを取得するためのクエリが発行されることになります。ループ内部の処理はループ回数分実行されることになるため、今回は Comment のテーブルのレコード数分だけループ内部の処理でクエリが発行されることになります。Comment のテーブルのレコード数を N とすれば、N 回クエリが発行されることになります。
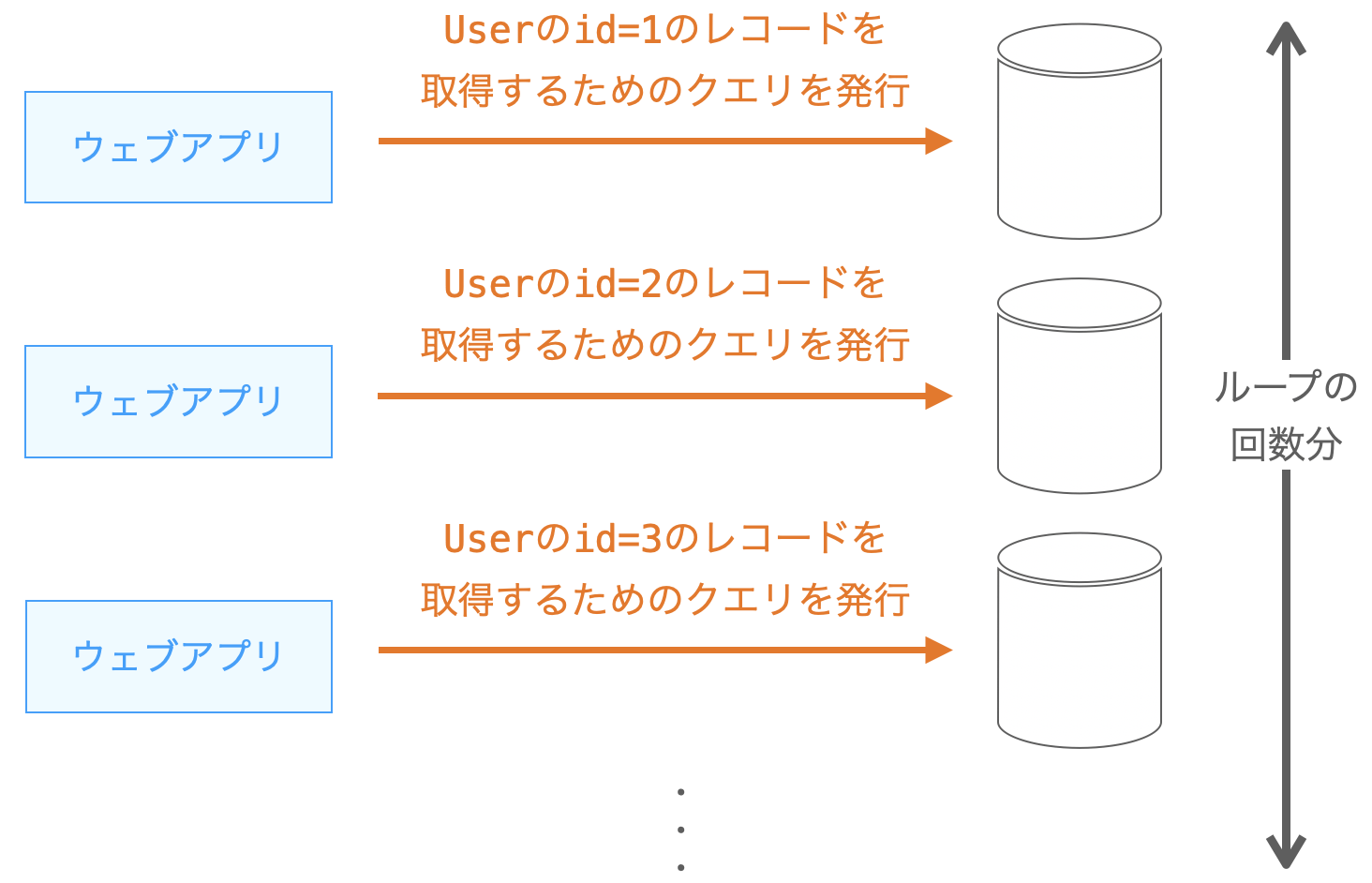
さらに、ループに入る前に Comment のテーブルの全レコードを取得するために 1 回クエリが発行されるため、合計で N + 1 回のクエリが発行されることになります。つまり、まさに上記の例は、N + 1 問題が発生する例となります。
テンプレートでのクエリの発行
また、上記ではビューで print によって comment.user.name の出力を行うことを想定した例となっていますが、同様の問題はテンプレートを利用した場合にも発生します。
例えばビューで下記のように Comment.objects.all() の結果をコンテキストの 'users' キーにセットして render 関数を実行するものとし、
comments = Comment.objects.all()
context = {
'comments' : comments
}
ret = render(request, 'app/comments.html', context)さらにテンプレートファイルで下記のように for ループの中で comment.user.name を出力するものとした場合も同様に N + 1 問題が発生することになります。
{% for comment in comments %}
<p>{{ comment.user.name }}</p>
{% endfor %}この場合は、下記で 1 回クエリが発行されることになり、
{% for comment in comments %}さらにループ内部の下記で N 回クエリが発行されることになります。
<p>{{ comment.user.name }}</p>当たり前と言えば当たり前なのですが、テンプレートを利用したとしても、結局ウェブアプリが所持していないレコードの情報は利用することができません。そのため、ウェブアプリが所持していないレコードを利用しようとする段階で、そのレコードを取得するためのクエリが発行されることになります。
そして、上記のように、タグ for を利用してレコードを複数表示するようなテンプレートファイルは多くの方が当たり前のように実装されている形式のコードになると思います。例えばユーザー一覧・コメント一覧などの一覧リストを表示するときは上記のような形式に自然となると思います。前述の通り、そのレコードが独立したものであれば問題ないですが、他のテーブルのレコードと関連付けされている場合、N + 1 問題が発生している可能性があります。ですが、Django フレームワークが裏側で自動的にクエリを発行してくれているので、N + 1 問題が発生していたとしても気づきにくいことになります。
もし、あなたがウェブアプリを開発したことがあるのであれば、是非そのアプリで N + 1 問題が発生していないかどうかを確認してみていただければと思います。特にリレーションを利用している場合、自然と for ループ内部で “for ループに入る前に取得したレコード以外” のレコードを利用している可能性があり、その場合は N + 1 問題が発生しているはずです。
N + 1 問題については大体理解していただけたでしょうか?
次は、N + 1 問題の解決方法について説明していきます。
N + 1 問題が発生する原因は、結局は for ループ内部で “for ループに入る前に取得したレコード以外” のレコードを利用しようとすることになります。先程の例でいえば、for ループに入る前に Comment のテーブルのレコードは取得したものの、for ループ内部で Comment のテーブルのレコードだけでなく、その Comment のテーブルのレコードに関連付けられた User のテーブルのレコードも利用しているため N + 1 問題が発生します。
であれば、リレーションを利用している場合は、for ループに入る前に、一方のテーブルのレコードを取得するだけでなく、それらのレコードに関連付けられている他方のテーブルのレコードも取得しておけば、この N + 1 問題は解決可能となります。
ただし、これらのレコードは単に別々のクエリを発行して取得しておくだけではダメで、Django から提供されるメソッドを利用して取得する必要があります。これらのメソッドが select_related と prefetch_related となります。これらのメソッドは両方とも、モデルクラスのデータ属性 objects (マネージャー) から実行可能なメソッドになります。
select_related は、関連付けされたレコード同士を結合した状態でレコードを取得してしまおう!という考え方で N + 1 問題を解決するメソッドになります。
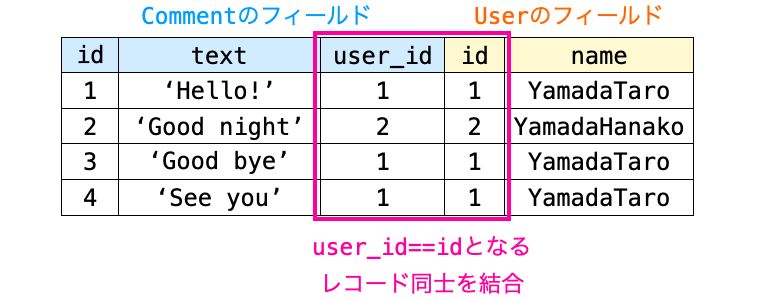
それに対し、レコードは結合はしないものの、関連付けられたレコードも一緒に取得しておき、一方のレコードから他方のレコードを参照できるように関連性も管理しておこう!という考え方で N + 1 問題を解決するのが後者の prefetch_related になります。
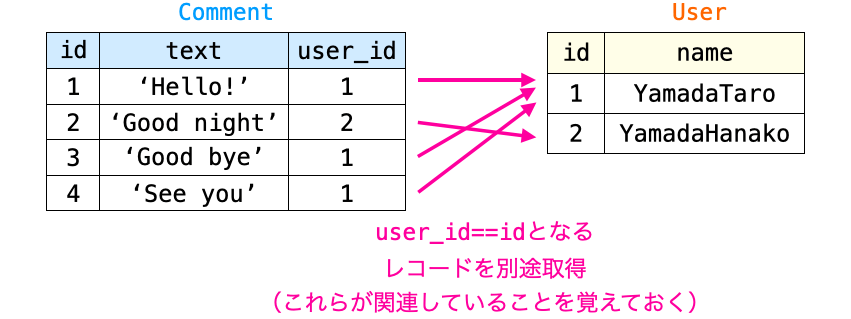
つまり、ループに入る前にレコードを取得する際に上記の select_related や prefetch_related を追加で実行するようにすれば、ループ内部で必要となる情報を全て含むレコードが事前に取得されることになるため、ループ内部でのクエリの発行を防ぐことができます。したがって、これらを利用した場合に必要となるクエリは N に比例して増えるのではなく、定数回で済むことになります。つまり N + 1 問題が解消されます。
先程少し説明しましたが、select_related はリレーションによって関連性を持つ2つのテーブルを結合するメソッドとなります。
select_related の基本的な使い方
select_related は下記のような形式で使用することになります。
モデルクラス.objects.select_related(引数)引数 には、リレーションフィールドを定義することによって モデルクラス のインスタンスに追加される “データ属性の名称” を文字列で指定します。
このデータ属性の名称に関しては リレーションフィールドの定義によって追加されるデータ属性の名称 でまとめていますので、詳細に関しては リレーションフィールドの定義によって追加されるデータ属性の名称 を参照してください。
例えば、下記のように User と Comment を定義した場合、User のインスタンスには comment_set というデータ属性が、Comment のインスタンスには user というデータ属性が追加されることになります。
from django.db import models
class User(models.Model):
name = models.CharField(max_length=256)
class Comment(models.Model):
text = models.CharField(max_length=256)
user = models.ForeignKey(User, on_delete=models.CASCADE)したがって、モデルクラス に Comment を指定した場合、引数 には下記のように 'user' を指定して select_related を実行する必要があることになります。
comments = Comment.objects.select_related('user')select_related の効果
select_related を実行することで、モデルクラス で指定したモデルクラスのテーブルの全レコードと フィールド名 で指定したフィールドで関連付けられるレコードとが “結合されたレコード” を取得するためのクエリが生成されることになります。あくまでもクエリは生成されるだけで、クエリの発行はレコードが必要になったタイミングで実行されます(また、後からクエリを上書きして取得するレコードの条件等を加えることも可能です)。
例えば、Comment のテーブルと User のテーブルがそれぞれ下の図のような状態である場合、
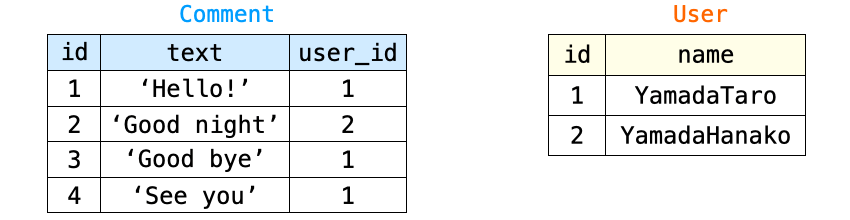
下記を実行した場合は、単に Comment のテーブルの全レコードを取得するクエリが生成されるだけになります。
comments = Comment.objects.all()具体的には、これによって生成されるクエリが発行されると下の図のようなレコードが取得されることになります。
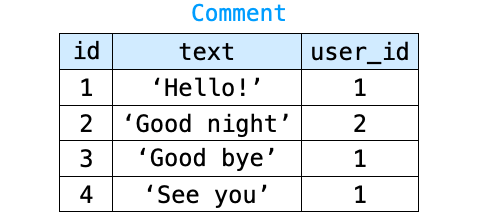
それに対し、下記のように select_related を実行した場合、単に Comment のテーブルの全レコードを取得するのではなく、各レコードと、そのレコードの user_id フィールドと一致するプライマリーキーが設定された User のテーブルのレコードとを結合することを要求するクエリが発行されることになります。
comments = Comment.objects.select_related('user')そして、クエリが発行された際には、それらが結合された状態のレコード取得されることになります。具体的には、下の図のようなレコードが取得されることになります。
select_related により N + 1 問題が解決される理由
で、ここで N + 1 問題が発生していた例で考えると、下記のように select_related を実行するようにすれば、上の図のような Comment のテーブルと User のテーブルとが結合された状態のレコードが取得されることになり、ループ内部での処理でクエリの発行が必要なくなります。なぜなら、ループに入る前に取得するレコードには User の name フィールドが含まれているからです。ループ内部で必要になる情報が全て取得済みのレコードに含まれているため、別途クエリを発行する必要はありません。
comments = Comment.objects.select_related('user')
for comment in comments:
print(comment.user.name)そして、この場合にクエリが発行されるタイミングは for comment in comments: のみとなり、発行されるクエリは下記のようなものとなります。
SELECT "app_comment"."id",
"app_comment"."text",
"app_comment"."user_id",
"app_user"."id",
"app_user"."name"
FROM "app_comment"
INNER JOIN "app_user"
ON ("app_comment"."user_id" = "app_user"."id")
上記は Comment のテーブル(app_comment)と User のテーブル(app_user)の2つのテーブルを結合し、その上でお互いのテーブルの全フィールドを含む全レコードを取得するクエリとなっています。テーブルを結合する際には、Comment のレコードに関連付けられた User のレコードが横に並べられる形で結合されます。前述の通り、どのレコード同士が関連付けられているかは Comment のレコードの user_id によって決まります。
上記のクエリを 1 回発行すれば、先ほど示したループの内部の処理ではクエリの発行が不要となるため、select_related を利用することでクエリの発行回数が N + 1 回から 1 回に削減されることになります。
クエリの発行回数が定数回となっているため、クエリの発行回数が表示するレコードの件数に比例して増加することを防ぎ、N + 1 問題を解決することができています。
select_related の様々な使い方
ちなみに、下記の2行ではどちらも同じクエリが生成されることになります。なので、どちらを使用しても良いです。
Comment.objects.select_related('user')
Comment.objects.select_related('user').all()また、全レコードではなく、条件を満たすレコードのみを取得するためのクエリを生成するのであれば、下記のように filter と組み合わせて実行すれば良いことになります。この場合、select_related で2つのテーブルを結合した状態で全レコードを取得するクエリを生成し、そのクエリを filter によって更新することになります。
Comment.objects.select_related('user').filter(条件)スポンサーリンク
次は prefetch_related について説明していきます。
prefetch_related の基本的な使い方
prefetch_related はリレーションによって関連性を持つ2つのテーブルのレコードを取得するメソッドとなります。prefetch_related は下記のような形式で使用することになります。
モデルクラス.objects.prefetch_related(引数)引数 には、select_related 同様に、リレーションフィールドを定義することによって モデルクラス のインスタンスに追加される “データ属性の名称” を文字列で指定します。
このデータ属性の名称に関しては リレーションフィールドの定義によって追加されるデータ属性の名称 でまとめていますので、詳細に関しては リレーションフィールドの定義によって追加されるデータ属性の名称 を参照してください。
例えば、下記のように User と Comment を定義した場合、User のインスタンスには comment_set というデータ属性が、Comment のインスタンスには user というデータ属性が追加されることになります。
from django.db import models
class User(models.Model):
name = models.CharField(max_length=256)
class Comment(models.Model):
text = models.CharField(max_length=256)
user = models.ForeignKey(User, on_delete=models.CASCADE)したがって、モデルクラス に User を指定した場合、引数 には下記のように 'comment_set' を指定して prefetch_related を実行する必要があることになります。
users = User.objects.prefetch_related('comment_set')prefetch_related の効果
prefetch_related を利用することで、モデルクラス で指定したモデルクラスのテーブルの全レコードを取得するためのクエリと、それらのレコードと関連付けられたレコードを取得するためのクエリが生成されることになります。
例えば、Comment のテーブルと User のテーブルがそれぞれ下の図のような状態である場合、
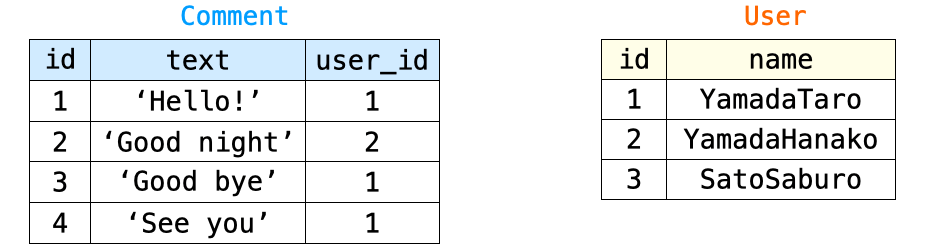
下記のように prefetch_related を実行すると2つのクエリが生成されることになります。1つ目が Comment のテーブルの全レコードを取得するクエリで、2つ目が、そのクエリによって取得される Comment のテーブルの “各レコードと関連づけられている User のテーブルのレコード” を取得するクエリとなります。
comments = Comment.objects.prefetch_related('user')したがって、上の図のようなテーブルの場合、Comment.objects.prefetch_related('user') によって生成されるクエリが発行されると下の図のような2つのテーブルのレコードが取得されることになります。
User のテーブルの id : 3 のレコードが取得されないのは、そのレコードと関連づけられている Comment のテーブルのレコードが存在しないから、すなわち、user_id が 3 であるレコードが存在しないからになります。
また、prefetch_related を利用した場合、2つのテーブルに対するクエリが別々に生成されることになりますが、これらのクエリの発行によって取得されたレコードはそれぞれ独立した状態ではなく、各レコードの関連性を保ったまま Django フレームワークによって管理されるようになります。後述でも例を示しますが、prefetch_related を利用せずに2つのテーブルに対して別々にクエリを発行すると、それぞれ独立したレコードとして扱われてしまうため、N + 1 問題を解決することができません。
prefetch_related により N + 1 問題が解決される理由
そして、ここで重要になるのは、prefetch_related を実行して生成されたクエリが発行されることでループ内で必要となるレコードが全て取得できる点と、これらの各レコードの関連性が Django フレームワークで管理されるという点になります。このため、N + 1 問題を prefetch_related によって解決することが可能となります。
例えば、下記のように prefetch_related を実行するようにすれば、prefetch_related で生成されたクエリが for comment in comments: 実行時に発行されることになります。そして、その発行によって Comment のテーブルの全レコードと、それらのレコードに関連付けられた User のレコードが取得されることになります。これらはクエリ発行時には独立した状態で取得されますが、別途 Django 内部で各レコードの関連性が管理されるようになります。
comments = Comment.objects.prefetch_related('user')
for comment in comments:
print(comment.user.name)したがって、ループ内部で Comment のレコードから User のレコードを参照しようとした際には、クエリを発行してレコードを取得するのではなく、既に取得したレコードの中から、その Comment のレコードと関連付けられている User のレコードを参照するようになります。そのため、ループ内では別途クエリを発行することが不要となり、発行されるクエリは prefetch_related で生成される2つのクエリのみで済むことになります。
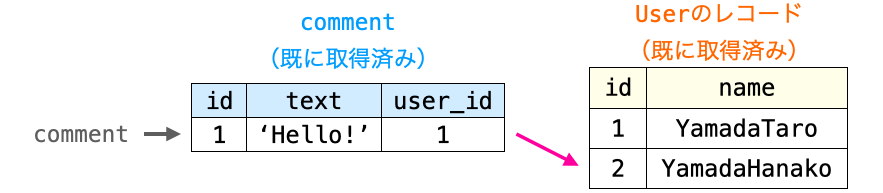
つまり、上記のループ処理を行なったとしても、クエリの発行回数は 2 回のみとなり、N + 1 問題を解消することができることになります。
関連性が管理されていない場合のクエリの発行
で、ここで重要になるのが、前述の通り prefetch_related を利用した場合は各レコードの関連性が Django フレームワークによって管理された状態になるという点になります。
例えば、少し無理矢理な例になりますが、下記のような処理を行なった場合、レコードの件数を求めるために全レコードが必要になるため、len(comments) で Comment の全レコードを取得するためのクエリが、len(users) で User の全レコードを取得するためのクエリがそれぞれ発行されることになります。したがって、for ループの処理は Comment とUser の全レコードが取得された状態で実行されることになります。
comments = Comment.objects.all()
users = User.objects.all()
len(comments)
len(users)
for comment in comments:
print(comment.user.username)ですが、この場合、Django フレームワークでは、Comment の各レコードと User の各レコードは独立したものとして扱われてしまいます。そのため、print(comment.user.username) 実行時には comment に関連付けられているレコードが未取得であると判断されてクエリが発行されることになります。つまり N + 1 問題が発生することになります。
このように、ループ内部の処理で必要になるレコードを全て取得していたとしても、それぞれのレコードの間の関連性が管理されていないと N + 1 問題が発生することになります。したがって、これらの関連性が管理されるようにレコードの取得を行う必要があり、それを行うためのメソッドが prefetch_related になります。
このページの前半の クエリは自動的に発行される の MEMO で、必要なレコードを取得していたとしてもクエリが発行されることがあると説明しましたが、まさに上記のように prefetch_related を利用せずにレコードを取得した場合がそれに該当します。
prefetch_related の様々な使い方
また、select_related 同様に、下記のように all と併用した場合も prefetch_related 単体で実行した場合と同じクエリが生成されることになります。
users = User.objects.prefetch_related('comment_set').all()さらに、下記のように filter と併用することで、取得する User のレコードの条件を指定することも可能です。
users = User.objects.prefetch_related('comment_set').filter(条件)さて、ここまで N + 1 問題の解決方法として select_related を利用する方法と prefetch_related を利用する方法の2つを紹介してきました。では、この2つはどのようにして使い分ければ良いでしょうか?
selected_related を利用するケース
どちらの方法でもクエリの発行回数が固定となって N + 1 問題は解決可能です。ですが、select_related の方がクエリ発行回数が 1 回のみで prefetch_related の場合は 2 回となり、クエリ発行回数で考えれば selected_related の方が良さそうですね!
なので、selected_related を使えるのであれば selected_related を使うので良いと思います。ですが、実は select_related は利用できるケースが限られているので注意してください。
具体的には、selected_related が実行可能なのは、メソッドを実行するモデルクラスに関連付け可能なインスタンスの個数が 1 である場合のみとなります。逆に、メソッドを実行するモデルクラスに関連付け可能なインスタンスの個数が 多 である場合、selected_related を実行すると例外が発生することになります。

関連付け可能なインスタンスの個数 で解説したように、各モデルクラスのインスタンスに関連付け可能なインスタンスの個数は、定義するリレーションフィールドの種類、および、そのインスタンスが “フィールドの定義先のモデルクラスのインスタンス” or “関連モデルクラス のインスタンス” のどちらであるかによって変化することになります。それをまとめた表が下の図となります。
メソッドを実行するモデルクラスに関連付け可能なインスタンスの個数が 1 である場合のみ selected_related が実行可能ということなので、OneToOneField を定義した場合、すなわち1対1のリレーションの場合は、OneToOneField を定義したモデルクラス、さらには 関連モデルクラス の両方から selected_related が実行可能ということになります。
また、ForeignKey を定義した場合、すなわち多対1のリレーションの場合は、ForeignKey を定義したモデルクラスのみ selected_related を実行可能ということになります。
そして、上記で紹介したモデルクラスに関しては selected_related が実行可能なので、N + 1 問題を解決するためには selected_related メソッドを実行するようにしてやれば良いということになります。
ちなみに、select_related が利用不可であるのにも関わらず実行してしまった場合、クエリ発行時に下記のような例外が発生することになります。
Invalid field name(s) given in select_related: 'comment_set'. Choices are: (none)
prefetch_related を利用するケース
そして、select_related が利用できない場合は、もう選択肢は1つしか残っていないので prefetch_related を利用するしかないです。
具体的には、多対多のリレーションを利用している場合は prefetch_related を、また多対1のリレーションを利用している場合は、ForeignKey を定義していない方のモデルクラス(関連モデルクラス)で prefetch_related を利用する必要があります。
例えば、ここまでの説明でも何度も紹介した User と Comment の定義の場合、User 側のテーブルからレコードを取得してから for ループを実行するのであれば、さらに、それによって N + 1 問題が発生するのであれば、N + 1 問題を解決するためには prefetch_related を利用する必要があります。
掲示板アプリの N + 1 問題を解決する
最後に、いつも通りの流れで、この Django 入門 の連載の中で開発してきている掲示板アプリに対し、N + 1 問題の解決を行なっていきたいと思います。
この Django 入門 に関しては連載形式となっており、ここでは以前に下記ページの 掲示板アプリでページネーションを利用してみる で作成したウェブアプリに対し、N + 1 問題が発生している箇所の修正を行なっていきたいと思います。
 【Django入門13】ページネーションの基本
【Django入門13】ページネーションの基本
現状、このアプリでは、「ユーザー一覧」と「コメント一覧」の2つのページの表示時に N + 1 問題が発生するようになってしまっています。
「ユーザー一覧」では、User のレコードのみを取得した状態で、その User のレコードに関連付けられている Comment のレコードの情報を表示しようとするため N + 1 問題が発生してしまっています。
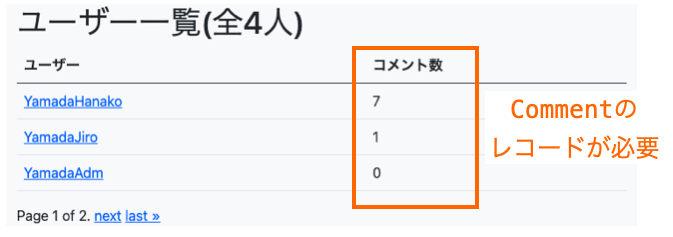
「コメント一覧」では、Comment のレコードのみを取得した状態で、その Comment のレコードに関連付けられている User のレコードの情報を表示しようとするため N + 1 問題が発生してしまっています。

前回の連載時に、これらのページではページネーションを行うようにしており、各ページで表示されるレコードの件数に上限が設けられるようになっています。なので、全レコードの件数に比例してクエリ発行回数が増加するのではなく、その表示するレコードの上限数に比例してクエリの発行回数が増えるようになっています。
したがって、ページネーションを行う前に比べると、1つのページを表示するために必要となるクエリの発行回数は減っています。ですが、それでもページに表示するレコードの件数に応じてクエリの発行回数は増えることになっていますので、その点の解決を行なっていきます。
スポンサーリンク
掲示板アプリのプロジェクト一式の公開先
この Django 入門 の連載を通して開発している掲示板アプリのプロジェクトは GitHub の下記レポジトリで公開しています。
https://github.com/da-eu/django-introduction
また、前述のとおり、ここでは前回の連載の 掲示板アプリでページネーションを利用してみる で作成したプロジェクトをベースに変更を加えていきます。このベースとなるプロジェクトは下記のリリースで公開していますので、必要に応じてこちらからプロジェクト一式を取得してください。
https://github.com/da-eu/django-introduction/releases/tag/django-pagination
さらに、ここから説明していく内容の変更を加えたプロジェクトも下記のリリースで公開しています。以降では、基本的には前回からの差分のみのコードを紹介していくことになるため、変更後のソースコードの全体を見たいという方は、下記からプロジェクト一式を取得してください。
https://github.com/da-eu/django-introduction/releases/tag/django-n1
N + 1 問題の発生個所
先ほど、「ユーザー一覧」と「コメント一覧」の2つのページの表示時に N + 1 問題が発生すると説明しましたが、もう少し詳細に N + 1 問題の発生個所について整理しておきたいと思います。
まず、現状の掲示板アプリでは、下記のような Comment を定義しており、Comment のインスタンスと CustomUser のインスタンスとで多対1の関連付けが行えるようになっています。
class Comment(models.Model):
text = models.CharField(max_length=256)
date = models.DateTimeField(auto_now_add=True)
user = models.ForeignKey(CustomUser, on_delete=models.CASCADE, null=True, related_name='comments')
コメント一覧表示時に発生する N + 1 問題
さらに、コメント一覧ページを表示するビューの関数 comments_view は下記のようになっています。
@login_required
def comments_view(request):
comments = Comment.objects.all().order_by('date')
paginator = Paginator(comments, 3)
number = int(request.GET.get('p', 1))
page_obj = paginator.page(number)
context = {
'page_obj' : page_obj
}
return render(request, 'forum/comments.html', context)そして、comments_view から利用されるテンプレートファイル comments.html の、コメント一覧を表示する箇所は下記のようになっています。page_obj は、Comment のインスタンスが割り付けられた Page のインスタンスとなります。
{% for comment in page_obj %}
<tr>
<td><a href="{% url 'comment' comment.id %}">{{ comment.text|truncatechars:20 }}</a></td>
{% if comment.user is not None %}
<td>{{ comment.user.username }}</td>
{% else %}
<td>不明</td>
{% endif %}
</tr>
{% endfor %}で、comments_view では Comment のインスタンスの取得のみが行われています(1行目)。そして、その状態で render 関数が実行されると、ウェブアプリが Comment のインスタンスのみを保持した状態でテンプレートファイルの解釈が行われることになり、{% for comment in page_obj %} によって page_obj に割り付けられた Comment のインスタンスに対する for ループが実行されることになります。
そして、このループの中で、comment.user により、ウェブアプリが保持していない CustomUser のインスタンス(comment に関連付けられた CustomUser のインスタンス)が必要となるため、ここで CustomUser のインスタンス取得用のクエリが発行されることになります。そして、このクエリの発行がループ回数分だけ行われることになるため、N + 1 問題が発生することになります。
ユーザー一覧表示時に発生する N + 1 問題
上記はコメント一覧ページを表示するビューの関数とテンプレートファイルに関する説明になりますが、下記に示したユーザー一覧ページを表示する users_view と user.html も同様の構造になっており、このページを表示する時にも N + 1 問題が発生することになります(下記における User は CustomUser を参照する変数になります)。
User = get_user_model()
@login_required
def users_view(request):
users = User.objects.all().order_by('date_joined')
paginator = Paginator(users, 3)
number = int(request.GET.get('p', 1))
page_obj = paginator.page(number)
context = {
'page_obj' : page_obj
}
return render(request, 'forum/users.html', context){% for user in page_obj %}
<tr>
<td><a href="{% url 'user' user.id %}">{{ user.username }}</a></td>
<td>{{ user.comments.all|length }}</td>
</tr>
{% endfor %}N + 1 問題の解決
では、先ほど説明した、コメント一覧ページ(Comment のインスタンス一覧)とユーザー一覧ページ(CustomUser のインスタンス一覧)の表示時に発生する N + 1 問題を解決していきたいと思います。
ここまでの説明からも分かるように、for ループが実行される前に、各モデルクラスのマネージャー(objects)から select_related or prefetch_related を利用して、そのモデルクラスのインスタンスと関連付けられたインスタンスもまとめて取得するようにしておけば、N + 1 問題が解決することになります。
利用するメソッド
ただし、先ほど示した Comment の定義からも分かるように、Comment に関連付け可能な CustomUser のインスタンスの個数は 1 であり、CustomUser に関連付け可能な Comment のインスタンスの個数は 多 となります。
そのため、N + 1 問題を解決するためには、Comment からレコードを取得する際に select_related を実行し、CustomUser からレコードを取得する際に prefetch_related を実行するようにしてやれば良いことになります。
メソッドの引数
また、リレーションフィールドの定義によって Comment に追加されるデータ属性の名称は 'user' であるため、select_related 実行時には引数に 'user' を指定する必要があります。
それに対し、CustomUser に追加されるデータ属性の名称は、related_name に指定した 'comments' となるため、prefetch_related 実行時には引数に 'comments' を指定する必要があります。
この辺りに注意しながら、N + 1 問題を解決していく必要があります。
変更後の views.py
ということで、ここまでの解説を踏まえると、下記のように views.py における users_views と comments_views を変更してやれば、コメント一覧ページとユーザー一覧ページの表示時に発生する N + 1 問題が解決できることになります。
# 略
User = get_user_model()
# 略
@login_required
def users_view(request):
users = User.objects.prefetch_related('comments').order_by('date_joined')
paginator = Paginator(users, 3)
number = int(request.GET.get('p', 1))
page_obj = paginator.page(number)
context = {
'page_obj' : page_obj
}
return render(request, 'forum/users.html', context)
# 略
@login_required
def comments_view(request):
comments = Comment.objects.select_related('user').order_by('date')
paginator = Paginator(comments, 3)
number = int(request.GET.get('p', 1))
page_obj = paginator.page(number)
context = {
'page_obj' : page_obj
}
return render(request, 'forum/comments.html', context)今回の掲示板アプリの変更は以上になります。いつもは動作確認を実施するのですが、今回はパフォーマンスの改善で見た目として動作確認結果が分かりにくいため、動作確認に関しては省略させていただきます。
前述でも触れた、下記ページで紹介している django-debug-toolbar を利用すれば、変更前に比べてクエリの発行回数が削減されていることを確認することができると思います。
【Django】発行されるクエリの確認方法(django-debug-toolbar)
スポンサーリンク
まとめ
このページでは、Django での N + 1 問題と、その解決方法について解説しました!
N + 1 問題とは、レコードの一覧を表示する際のクエリの発行回数が N + 1 回になってしまうことを言います。この N は表示するレコードの件数となります。このようにクエリの発行回数がレコードの件数に比例して増加してしまうと、レコードの件数が増えるたびにアプリの処理速度が低下することになります。
そのため、クエリの発行回数が N に比例しないようにすることが重要であり、これは select_related と prefetch_related のいずれかを利用することで解決することが可能です。select_related に関しては利用できるケースが限られているため、状況に応じてこれらを使い分けることが必要となります。
N + 1 問題が発生する原因は「所持していないレコードの情報はデータベースから取得してからでないと表示できない」という当たり前の前提に基づいて考えれば自然と理解できると思います。ぜひ、この前提を頭に入れて、自身のウェブアプリで N + 1 問題が発生していないかどうかを確認し、発生している場合は select_related や prefetch_related を利用して問題を解決してみてください。
また、クエリの発行タイミングや発行回数は、下記ページでも紹介している django-debug-toolbar でも確認できますので、こういったツールを利用して自身のウェブアプリが発行するクエリについて調べてみるのも良いと思います!
【Django】発行されるクエリの確認方法(django-debug-toolbar)
おすすめ書籍
クエリそのものやデータベースに興味が出てきた方には、別途書籍等でデータベース・SQL・クエリなどについて学んでみても良いと思います。特に下記の スッキリわかるSQL入門 第3版 ドリル256問付き! は、初心者の方でもクエリについて理解しやすい内容となっておりオススメです。こういった書籍でクエリについて学べば、Django でどんな処理を行えばどんなクエリが発行されるのかをイメージしながらウェブアプリ開発が行えるようになりますし、特にパフォーマンスの改善等に、この知識を活かすことができると思います。