
この記事はC言語演習問題集の問題の回答です。まだ問題読んでないという方は下記記事の「日本語って難しい!マルチバイト文字をC言語で扱ってみよう」をぜひ見てから読んでください。
 C言語応用問題集
C言語応用問題集
解答例
#include <stdio.h>
#include <string.h>
int main(void){
char input[256];
char target[256] = "人";
unsigned int inputLen;
unsigned int targetLen;
int i, j;
int num;
printf("日本語を入力してください:");
scanf("%s", input);
inputLen = strlen(input);
targetLen = strlen(target);
printf("inputLen = %d, targetLen = %d\n", inputLen, targetLen);
for(i = 0; i < inputLen; i++){
printf("%c", input[i]);
}
printf("\n");
for(j = 0; j < targetLen; j++){
printf("%c", target[j]);
}
printf("\n");
num = 0;
for(i = 0; i < inputLen - targetLen + 1; i++){
j = 0;
if(input[i] == target[0]){
for(j = 0; j < targetLen; j++){
if(input[i + j] != target[j]){
break;
}
}
if(j == targetLen){
num++;
}
}
}
if(num > 0){
printf("「%s」を%d回発見!\n", target, num);
} else {
printf("「%s:なし!\n", target);
}
return 0;
}表示例

スポンサーリンク
解説
今回は文字列を扱ってみました。結構C言語の参考書って、1バイトで扱える英語のみを扱って終わり!というパターンが多いのですが、ここでは日本語を扱ってみています。日本語は文字の種類が多いので1バイトでは表現しきれず、複数バイトを用いて表現されています。わたしも実際に何バイト使用しているかは知らなかったのですが、実際に試してみたら1文字3バイト使用しているようでした(これは環境によるかも)。
それではプログラムを追いながらポイントを見ていきましょう。
char target[256] = "人"; printf("日本語を入力してください:");
scanf("%s", input);
inputLen = strlen(input);
targetLen = strlen(target);inputとtargetの両方に日本語が入力されます。表示例で使用した例だとinputは「日本人アメリカ人大阪人」で普通に考えれば11文字です。targetは「人」にしていますので3文字のはずです。しかし表示例ではそれぞれ33文字、3文字であると出力されています。
これは上で説明したように日本語が1文字3バイトで扱われ、strlen関数が1文字1バイトであることを前提として計算しているからです。
英語と日本語の文字列はchar配列内で下記のように格納されることになります。char型の配列は1要素が1バイトでありますが、1文字分とは限らないというのがこの問題のポイントです。
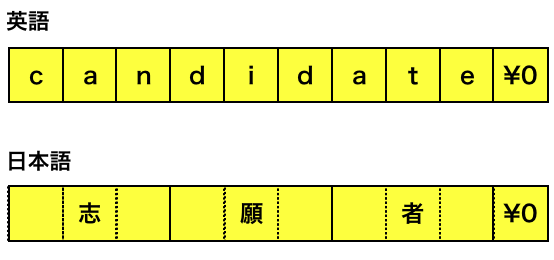
なので、日本語のある文字が含まれているかを確認するためには1バイト分だけでなく3バイト分調べてやる必要があります。
for(i = 0; i < inputLen - targetLen + 1; i++){
j = 0;
if(input[i] == target[0]){
for(j = 0; j < targetLen; j++){
if(input[i + j] != target[j]){
break;
}
}
if(j == targetLen){
num++;
}
}
}targetLenが3なのでchar型の要素を3つ分調べてやれば3バイト分確認したことになります。3バイト分連続して同じデータが格納されていれば同じ文字が含まれると判断してnumをインクリメントしています。
ちなみに日本語文字列を扱う変数の型としてwchar_tなども存在します。今回は日本語文字がマルチバイト文字であることを実感してもらうためにchar型を使用しましたが、実践ではwchar_tを使用する方が直感的に分かりやすいプログラムが作成できると思います。
独り言
正直自分も日本語を扱うプログラムは初めて書きました。もしかしたらこうやるのかも・・・・!と思ってやってみたら思った通りに動いてくれたので問題文にしてみました。文字列扱うのってC言語では実は結構難しいしバグりやすい部分だと思います。それを日本語でやるとさらに難しいですね・・・。
オススメの参考書(PR)
C言語学習中だけど分からないことが多くて挫折しそう...という方には、下記の「スッキリわかるC言語入門」がオススメです!

まず学習を進める上で、参考書は2冊持っておくことをオススメします。この理由は下記の2つです。
- 参考書によって、解説の仕方は異なる
- 読み手によって、理解しやすい解説の仕方は異なる
ある人の説明聞いても理解できなかったけど、他の人からちょっと違った観点での説明を聞いて「あー、そういうことね!」って簡単に理解できた経験をお持ちの方も多いのではないでしょうか?
それと同じで、1冊の参考書を読んで理解できない事も、他の参考書とは異なる内容の解説を読むことで理解できる可能性があります。
なので、参考書は2冊持っておいた方が学習時に挫折しにくいというのが私の考えです。
特に上記の「スッキリわかるC言語入門」は、他の参考書とは違った切り口での解説が豊富で、他の参考書で理解できなかった内容に対して違った観点での解説を読むことができ、オススメです。題名の通り「なぜそうなるのか?」がスッキリ理解できるような解説内容にもなっており、C言語入門書としてもかなり分かりやすい参考書だと思います。
もちろんネット等でも色んな観点からの解説を読むことが出来ますので、分からない点は別の人・別の参考書の解説を読んで解決していきましょう!もちろん私のサイトも参考にしていただけると嬉しいです!
入門用のオススメ参考書は下記ページでも紹介していますので、こちらも是非参考にしていただければと思います。
https://daeudaeu.com/c_reference_book/